Функционирования распределенной архитектуры
Описанная выше картина представляет собой функционально-ориентированный взгляд на систему и имеет статический характер. Для получения динамической картины работы всей системы следует обратить внимание на диаграмму кооперации на рис. 4.1.

Рис. 4.1 Функционирование системы
На данной диаграмме умышленно опущены детали и моменты ветвления потока управления системы для того, чтобы выделить главную идею работы, не погружаясь в детали. Распишу событийную модель по шагам:
Пользователь воздействует на Вид (View) клиентского приложения.
Вид делегирует событие Посреднику (Mediator).
Посредник обращается к Заводу (FactSourceFactory), чтобы тот создал Proxy-объект, поддерживающий интерфейс FactSourceInterface для работы с фактами.
Медиатор вызывает Контроллер (Controller) который отвечает за обработку данного типа события пришедшего от пользователя.
Контроллер посылает запрос к созданному Proxy-объекту на 3 шаге.
Proxy-объект, поддерживающий интерфейс FactSourceInteface, делегирует запрос к Источнику Фактов (AbstractFactSource) в ядре, находящемуся на стороне сервера приложения. На этом шаге происходит сетевой вызов, который проходит через стаб (stub) клиентского приложения и скелетон (skeleton) сервера приложения, где реализуется взаимодействие на одной из технологий RMI, CORBA, DCOM или др.
На стороне сервера происходит аутентификация с помощью завода, отвечающего за безопасность (SecurityFactory). Процесс аутентификации происходит только при первом обращении клиентского приложения к серверу приложений.
Происходит процесс авторизации, во время которого выясняются права доступа пользователя.
Ядро запрашивает Метамодель (MetaModel) у Завода Метаданных (MetaFactory) для описания факта, с которым взаимодействует пользователь.
Завод Метаданных извлекает запрашиваемую Метамодель.
Ядро запрашивает Метамодель на предмет Картриджа (FactCartridge), в котором находится факт.
Метамодель берет Картридж, в котором находится искомый факт.
Для доступа к фактам для разных типов источников данных ядро запрашивает у Картриджа объект, поддерживающий интерфейс FactDAO.
Картридж запрашивает этот объект у Завода Доступа к Фактам (FactDAOFactory), который создает эти объекты.
Завод Доступа к Фактам создает запрашиваемый объект.
Ядро делегирует объекту запрос от Контроллера клиентского приложения.
Объект, поддерживающий интерфейс FactDAO, производит изменения факта (Fact).
Управление возвращается в Контроллер клиентского приложения, производящий коррекцию Модели (Model).
Медиатор посылает сообщение об обновлении Модели Виду, и он производит свою перерисовку.
создание простейшего приложения
Теперь попробуем создать простейшее приложение, позволяющее вводить текст в редактируемое поле и добавлять этот текст к списку при нажатии мышью на кнопку. Выберем пункт меню File/New Application для создания проекта и сохраним его главную форму под именем samp1.cpp, а сам проект под именем samp.mak. Поместим на форму компоненты Button, Edit и ListBox со страницы Standard палитры компонент.

Рис. 9. Размещение компонентов на форме
После этого выберем на форме компонент Edit и удалим текущее значение свойства Text. Затем установим свойство Caption для Button1 равным "Добавить".
Чтобы добавить обработчик события OnClick для кнопки Добавить, нужно выбрать эту кнопку на форме, открыть страницу событий в инспекторе объектов и дважды щелкнуть мышью на колонке справа от события OnClick. В соответствующей строке ввода появится имя функции. C++ Builder сгенерирует прототип обработчика событий и покажет его в редакторе кода. После этого следует ввести следующий код в операторные скобки { ... } тела функции: void __fastcall TForm1::Button1Click(TObject *Sender) { if (!(Edit1->Text == "")) { ListBox1->Items->Add(Edit1->Text); Edit1->Text = "" ; } }
Для компиляции приложения в меню Run выберем пункт Run. Теперь можно что-нибудь ввести в редактируемое поле, нажать мышью на кнопку Добавить и убедиться, что вводимые строки добавляются к списку.

Рис.10. Так выглядит готовое приложение.
Теперь модифицируем приложение, добавив кнопки Удалить и Выход. Для этого добавим еще две кнопки, изменим их свойство Caption и создадим обработчики событий, связанных с нажатием на эти кнопки:

Рис. 11. Модифицированное приложение
Для кнопки Удалить:
void __fastcall TForm1::Button2Click(TObject *Sender) { if (!(ListBox1->ItemIndex == -1)) ListBox1->Items->Delete(ListBox1->ItemIndex); }
Для кнопки Выход:
Close();
Сохраним и скомпилируем приложение, а затем протестируем его.
Итак, мы познакомились со средой разработки Borland C++ Builder и создали простое приложение. В следующих статьях этого цикла будут описаны приемы манипуляции компонентами на форме и более подробно рассмотрены особенности поведения различных компонентов в приложении.
Координаты автора: Центр Информационных Технологий,
тел. (095)932-92-12, 932-92-13,
Проблема изоморфизма пересечения языковых пар
Итак, мы определили, что представление на языке UNL позволяет полностью сохранить смысл (поскольку лексическими единицами являются однозначные обозначения понятий) и обеспечивает независимость изоморфизма пересечения языковых пар от порядка слов в предложениях. Тем не менее, осталась и усугубилась проблема нарушения изоморфизма, вызванного различием форм одного и того же слова в разных предложениях. Действительно, концепт в языке UNL, не меняет своей формы, с каким бы другим концептом он ни был связан. В то же время, одно и то же слово на естественном человеческом языке может видоизменяться.
Анализируя эту проблему, задумаемся: а действительно ли нам нужно вычислять пересечение исходных сегментов? Нельзя ли, вычислив пересечение целевых сегментов (то есть UNL-предложений), сформировать для него перевод обратно на исходный язык автоматически? Положительный ответ на эти вопросы можно дать, если снова воспользоваться технологией машинного перевода. Действительно, для всех концептов имеется их перевод на исходный язык, следовательно, слабое место машинного перевода- выбор лексики- удастся избежать. Все, что будет требоваться от компьютера- это выделить в исходном сегменте те слова и синтаксические связи, которые вошли в состав пересечения UNL-предложений, и сформировать новое словосочетание, нужным образом изменив формы слов (рис. 7).
Рис. 7
Коль скоро мы доверили системе машинного перевода синтаксический и морфологический разбор исходного сегмента, когда оценивали изоморфизм пересечения языковых пар без привлечения UNL, доверим ей сделать то же самое для организации поиска сегмента в памяти переводов. В самом деле, почему бы не преобразовать исходный сегмент в UNL-предложение и не осуществить поиск в графе сегментов, хранящих текст на языке UNL? Поступив подобным образом, мы полностью избавимся от необходимости осуществлять операции поиска и добавления над графом сегментов, хранящих текст на естественном языке. Все операции будут производиться над графом UNL-предложений. Теперь вместо нескольких графов (по одному на каждый язык) память переводов будет использовать один единственный граф, каждый узел которого будет представлять собой языковую звезду с UNL-предложением в центре и вариантами перевода на лучах.
Весь процесс работы переводчика с предлагаемой системой описывается схемой, изображенной на рис. 8.

Рис. 8
Важным фактором является то, что работа классической памяти переводов описывается такой же схемой. Это означает, что реализация предлагаемой модели может быть легко встроена в существующие системы.
Проблемы использования метаданных в клиентских приложениях.
Информационные системы, основанные на архитектуре клиент-сервер, приобрели заметную популярность в течение последних нескольких лет. В достаточном количестве имеются инструменты для графического проектирования серверных частей подобных информационных систем (так называемые средства). Однако до сих пор не сформулирована универсальная концепция использования в клиентских приложениях информации, содержащейся в созданной с помощью инструментов модели данных (так называемых метаданных).
Нередко приходится в процессе разработки производить определение метаданных дважды: при создании серверной части информационной системы и при создании клиентских приложений, что потенциально является источником ошибок и несогласованности метаданных серверной и клиентских частей информационной системы. По той же причине поддержка и сопровождение проекта становятся весьма проблематичными при усложнении модели данных, а разработка интерфейсов пользователя, основанных на сложных структурах данных, предъявляет высокие требования к разработчику даже в случае использования таких совершенных инструментов, как Borland Delphi. Кроме того, часто доступ к модели данных желателен не только в процессе проектирования, но и в процессе выполнения приложения, особенно когда информационная система подвергается модернизации, так как при этом. процесс сопровождения информационной системы требует меньших временных и финансовых затрат.
Эта проблема может быть решена путем создания утилит, способных осуществлять двухсторонний обмен метаданными между словарем данных средства разработки и ER-диаграммой средства, и компонентов, способных использовать метаданные не только во время проектирования, но и во время выполнения. Попытка сделать первое была реализована в эксперте из комплекта поставки Delphi 2.01, осуществляющем односторонний перенос расширенных атрибутов из ER-диаграмм популярных средств в словарь данных Delphi, однако это было лишь частичным решением проблемы, так как при этом невозможен перенос метаданных обратно из словаря данных в ER-диаграмму, да и с ERwin этот эксперт работает некорректно. Что касается второго - создания чувствительных к метаданным компонентов, эта проблема решается с помощью предлагаемого вашему вниманию инструмента MetaBASE (ERwin for Delphi), поставляемого в комплекте с известным средством ERwin компании Logic Works.
Продуктивность программирования
Продуктивность программирования определяет, насколько эффективно (т.е. быстро и точно) программист с определенным опытом и знаниями может решить поставленную перед ним задачу, используя заданный язык программирования. Так как оклад разработчика является главной составляющей стоимости разработки любого программного проекта, продуктивность программирования имеет большое значение. Также в определенной степени продуктивность программирования определяется доступными инструментальными средствами.
Отличительной особенностью Java в сравнении с другими языками программирования общего назначения является обеспечение высокой продуктивности программирования, нежели производительность работы приложения или эффективность использования им памяти.
Для этого Java наделена некоторыми дополнительными возможностями. Например, в отличие от C++ (или C), программист не должен в явном виде "освобождать" (возвращать) выделенную память операционной системе. Освобождение неиспользуемой памяти (сборка "мусора") автоматически обеспечивается средой выполнения Java в ущерб производительности и эффективности использования памяти (см. далее). Это освобождает программиста от утомительной задачи по слежению за освобождением памяти - главного источника ошибок в приложениях. Одна эта возможность языка должна значительно увеличить продуктивность программирования в сравнении с C++ (или C).
Однако проведенное исследование показывает, что на практике сборка "мусора" и другие возможности Java не оказывают большого влияния на продуктивность программирования. Одна из классических моделей оценки программного обеспечения CoCoMo, предложенная Barry Boehm, предопределяет стоимость и сроки разработки программного продукта на основе стоимостных коэффициентов, которые учитывают такие факторы, как суммарный опыт программирования разработчика, опыт программирования на заданном языке, желаемая надежность программы и т.д. Boehm пишет, что независимо от уровня используемого языка, начальные трудозатраты всегда высокие.
Подобная методика подсчета использовалась в другом исследовании, проведенном C.E.Walston и C.P.Felix, IBM, Метод измерения и оценки программирования ( A method of programming measurement and estimation) .
Оба приведенных здесь исследования появились задолго до создания Java, но несмотря на это, они демонстрируют общий принцип: сложность языка программирования общего назначения по сравнению с другими аспектами, такими как квалификация разработчика, не оказывает существенного влияния на полную стоимость разработки проекта.
Существует более позднее исследование, которое явно включает Java и которое подтверждает эту гипотезу. В Эмпирическом сравнении C, C++, Java, Perl, Python, Rexx и Tcl (An empirical comparison of C, C++, Java, Perl, Python, Rexx, and Tcl) Lutz Prechelt из университета Karlsruhe описывает проведенный им эксперимент, в котором студентам информатики поручили выполнить определенный проект и выбрать для его реализации, руководствуясь личными предпочтениями, один из языков программирования: C, C++ или Java (остальные языки были рассмотрены в другой части исследования). Собранные данные показали почти одинаковые результаты для C++ и Java (C был на третьем месте по многим параметрам). Эти результаты подтверждаются нашим собственным опытом: если программисты вольны в самостоятельном выборе языка программирования (чаще руководствуясь при этом своим опытом), программисты с равным опытом работы (например, измеренным в годах) достигают одной и той же продуктивности. Второй интересный аспект, который бы мы хотели отметить (но который не имеет формального экспериментального подтверждения), заключается в том, что менее опытные разработчики достигают лучших результатов с Java, разработчики со средним опытом разработки достигают одинаковых результатов с обоими языками программирования, опытные разработчики достигают лучших результатов с C++. Эти наблюдения могут быть объяснены тем, что для C++ доступны более совершенные средства разработки; и этот факт тоже должен быть принят во внимание.
Интересный способ определения продуктивности программирования предлагает метод функциональных единиц (Function Point), разработанный Capers Jones.Функциональная единица - это метрика программного обеспечения, которая зависит лишь от его функциональности, а не от конкретной реализации. Эта метрика позволяет использовать в качестве критерия оценки продуктивности программирования число строк кода, необходимых для обеспечения одной функциональной единицы, в свою очередь, уровень языка определяется числом функциональных единиц, которые могут быть созданы за определенное время. Интересно, что обе величины: число строк кода на единицу функциональности и уровень языка одинаковы для обоих языков (уровень языка: C++ и Java - 6, C - 3.5, Tcl - 5; число строк кода на единицу функциональности: C++ и Java - 53, C - 91, Tcl - 64).
Подводя итог: оба исследования и практика опровергают утверждение, что Java обеспечивает программистам лучшую продуктивность программирования, нежели C++.
Проектирование формы приложения
Попробуем использовать полученные знания для создания текстового редактора, с помощью которого можно было бы создавать новые файлы, открывать имеющиеся, ре актировать и сохранять их, а также использовать буфер обмена для работы с фрагментами текста. Для этого создадим новый проект, основанный на пустой форме, и сохраним ее под именем Edit1.cpp. Сам проект сохраним под именем Edit.mak.
На пустой форме разместим компонент TPanel - будущую инструментальную панель нашего редактора. Свойству Align полученного компонента Panel1 присвоим значение alTop, а свойству Caption - пустую строку.
Далее разместим на форме компонент TMemo и присвоим его свойству Align значение alClient, свойству ScrollBars - значение ssVertical, а свойству Lines - пустой массив строк (редактор свойств, являющихся строковыми массивами, как п авило, представляет собой обычный текстовый редактор).
Вспомним о том, что наш будущий текстовый редактор должен открывать и сохра ять файлы. Для этой цели воспользуемся стандартными диалогами Windows 95, содержащимися в библиотеке comdlg32.dll. Для этого поместим на форму два диалога со страницы Dialogs: TOpenDialog и TSaveDialog. Изменим свойство Filter созданного только что компонента OpenDialog1, внеся две строки в диалоговую панель Filter Editor и нажав кнопку OK (рис. 8).

Рис. 8. Установка свойства Filter компонента OpenDialog1.
Теперь можно взять в буфер обмена строку, образовавшуюся в колонке значений апротив свойства Filter, выбрать компонент SaveDialog1 и вставить содержимое буфера обмена в строку напротив свойства Filter. Этим самым мы установим такое же значение свойства Filter для второго диалога. При желании можно изменить заголовки диалоговых панелей (свойство Caption) и другие параметры (свойство Options).
Обратите внимание на то, что языковая версия библиотеки может быть в общем случае как русской, так и английской, так как это ресурс Windows, а не вашего приложения. Поэтому, если вашим пользователям нужно, чтобы стандартные диалоги Windows были русскоязычными, рекомендуйте им установить русскую версию Windows 95 или Windows NT Workstation, либо попробуйте заменить на компьютерах пользователей имеющуюся версию comdlg32.dll на русскоязычную.
Впрочем, на странице System имеется достаточное количество компонент для создания "самодельных" диалогов для работы с файлами... И, наконец, разместим на форме компонент StatusBar со страницы Win95. Отредактируем его свойство Panels (это свойство представляет собой набор компонентов-панелей, на которых выводится необходимая пользователю информация). Редактор этого свойства представляет собой диалог (рис.9). Создадим панель, на которой будет появляться имя редактируемого файла. Для этого нажмем кнопку New и изменим параметр Width созданной панели, сделав его равным 100. В поле Text введем значение "Без имени". Затем нажмем кнопку ОК.



Программная модель командира
В формулировке задачи нет ни слова о том, откуда берется команда. Будем считать, что ее подает командир и что он делает это, переходя во внутреннее состояние "Огонь". Заголовочный файл и реализация методов для класса "Командир" (Officer) представлены в листинге 2.
Алгоритм функционирования командира прост (но роль его важна!): это циклические переходы из состояния "Сон" в состояние "Огонь". Из "Сна" командира можно вывести принадлежащим ему методом SetCommand.
Программная модель стрелка
Имея алгоритм решения задачи и модель поведения стрелка, можно приступить к программированию. Заголовочный файл и реализация класса "Стрелок" (Rifleman) показаны в листинге 1.
У класса CRifleman, порожденного из автоматного класса LFsaAppl, имеется три предиката, три действия и таблица переходов автомата. Находясь в начальном состоянии "Сон" ("солдат спит - служба идет"), стрелок ждет команды "Огонь!", которой соответствует одноименное внутреннее состояние соседа слева (адрес соседа находится в указателе pFsaLeftMan). Анализ такой ситуации в автомате выполняет предикат x1.
При поступлении команды "Огонь!" автомат выполняет действие y1 и переходит в состояние "Огонь". Действие y1 присваивает автомату номер на единицу больше, чем у соседа слева, а состояние "Огонь" сигнализирует соседу справа о том, что дана команда открыть стрельбу.
Находясь в состоянии "Огонь", стрелок ожидает, чтобы сосед справа (адрес которого хранится в указателе pFsaRightMan) перешел в состояние "Готов", определяя соответствующий момент по истинности предиката x2. Когда это случается, он сам переходит в состояние "Готов" и выполняет действие y2, т. е. уменьшает на единицу свой номер.
Затем начинается автономная работа стрелка - уменьшение на единицу своего номера при каждом такте работы автомата. При равенстве номера нулю автомат переходит в состояние "Выстрел". При этом выполняется действие y3.
Состояние "Выстрел" послужит сигналом для пули, которая начнет свой "разящий полет" от одной границы окна к другой (напомним, что в качестве пули мы используем мячик из статьи [1]). О роли действий y3, y4, y5 и предиката x4 будет рассказано в разделе о стрельбе очередями.
Производительность работы приложений
Мы увидели, что преимущества продуктивности программирования на Java оказались иллюзорными. Теперь мы исследуем производительность работы приложений.
И снова Prechelt предоставляет интересные сведения. Объем предлагаемой им информации огромен, но в конечном итоге он приходит к заключению, что "Java-программы выполняются по крайней мере в 1.22 раза медленнее C/C++ программ". Заметьте, что он сказал по крайней мере; средняя же скорость работы Java-программ гораздо меньше. Наш собственный опыт показывает, что Java-программы выполняются приблизительно в 2-3 раза медленнее своих C/C++ аналогов. На задачах, ориентированных на интенсивное использование процессора, Java-программы проигрывают еще сильнее.
В случае программ с пользовательским графическим интерфейсом увеличение времени отклика интерфейса является более критичным, чем низкая производительность программы. Проведенные исследования показывают, что пользователи более терпимы к задачам, выполняющимся в течение двух или трех минут, чем к программам, которые не реагируют мгновенно на их воздействия, например, на нажатия кнопок. Эти исследования показывают, что если время отклика программы больше, чем 0,7 секунды, пользователи считают ее медленной. Мы вернемся к этой проблеме, когда будем сравнивать пользовательский графический интерфейс в программах Java и C++.
Объяснение того, почему Java-программы медленнее C++ проограмм, заключается в следующем. C++ программы компилируются компилятором C++ в двоичный формат, который затем исполняется непосредственно процессором; таким образом, выполнение программы осуществляется аппаратными средствами. (Это несколько упрощенно, так как большинство современных процессоров выполняют микрокод, но это не принципиально при обсуждении данного вопроса.) С другой стороны, компилятор Java компилирует исходный код в "байт-код", который непосредственно исполняется не процессором, а с помощью другого программного обеспечения, виртуальной машины Java (Java Virtual Machine, JVM).
В свою очередь, JVM исполняется процессором. Таким образом, выполнение байт-кода Java-программ осуществляется не быстрыми аппаратными средствами, а с помощью более медленной программной эмуляции.
Для повышения производительности работы Java-программ были разработаны "Just in Time" (JIT) компиляторы, но универсального решения этой проблемы не существует.
На первый взгляд, полуинтерпретируемая природа Java-программ обеспечивает выполнение принципа "скомпилированный однажды код выполняется везде". Однажды скомпилированная в байт-код Java-программа может выполняться на любой платформе, для которой доступна JVM. На практике же, это не всегда так из-за отличий в реализациях разных JVM и из-за необходимости иногда наряду с Java-программами использовать родной, не-Java код, обычно написанный на C или C++.
Но разве использование платформенно-независимого байт-кода является верным подходом в создании кросс-платформенных приложений? С хорошим кросс-платформенным инструментарием, наподобие Qt, и хорошими компиляторами для различных платформ программисты могут достичь почти той же цели компиляцией своего исходного кода один раз для каждой из платформ: "написанный однажды код компилируется везде". Можно возразить, что для этого разработчикам потребуется доступ ко всем поддерживаемым платформам, в то время, как с Java, теоретически, разработчикам необходим доступ только к одной из платформ, имеющей средства разработки для Java и JVM. На практике же ни один из ответственных производителей программного обеспечения не будет сертифицировать свои программные продукты для платформ без предварительного их тестирования, поэтому в любом случае производителям будет необходим доступ ко всем поддерживаемым платформам.
Возникает вопрос, зачем использовать программную реализацию виртуальной машины Java, если такую же функциональность можно получить с помощью аппаратной реализации? Именно так рассуждали разработчики при создании языка Java; они предполагали, что вопрос низкой производительности будет решен, когда станет доступной аппаратная реализация JVM в виде Java-процессоров.Однако даже по прошествии пяти лет Java-процессоры не получили широкого распространения. Существуют проектные экземпляры и даже работающие прототипы Java-процессоров, однако понадобится еще немало времени, чтобы стало возможным их приобрести.
Prolog_facts.shtml
Сортировка фактов ПРОЛОГа
Ермолаев Д.С., Москва
09.04.2002
Программа на ПРОЛОГе оперирует с базой знаний, состоящей из фактов. Как правило, поиск решения идет с помощью перебора всех возможных фактов. Это может привести к значительным потерям времени. Поэтому, иногда необходимо отсортировать факты так, что бы программа начинала просмотр знаний с наилучшего варианта для ускорения поиска решения. Здесь предложен алгоритм сортировки фактов языка ПРОЛОГ. Алгоритм и его реализация на Visual Prolog 5.2 была сделана мною за 3 часа. Я не знаю какой это метод, потому как сам его придумал. Я слышал что есть метод с какими-то пузырьками, возможно это его подобие :)
------------------------------------
domains
ИмяЗаписи = string НомерЗаписи, ЗначениеЗаписи = integer МояЗапись=моя_запись(НомерЗаписи, ИмяЗаписи, ЗначениеЗаписи); пусто
database - мои_записи мз(МояЗапись)
predicates
показать_мои_записи значение_записи(МояЗапись,ЗначениеЗаписи) запись_выбрать(МояЗапись З1, МояЗапись З2, МояЗапись Вставить, МояЗапись Наверх) запись_вставить(МояЗапись) сортировка(МояЗапись Вниз, МояЗапись Вверх) - (i,o) сортировка откат
clauses
откат:-fail.
% взять значение записи
значение_записи(моя_запись(_,_,Значение),Значение):-!.
% выбрать какую запись добавить, а какую передать наверх
запись_выбрать(Запись1,пусто,пусто,Запись1):-!. запись_выбрать(Запись1,Запись2,Запись1,Запись2):- значение_записи(Запись1,Значение1), значение_записи(Запись2,Значение2), Значение1>Значение2, !. запись_выбрать(Запись1,Запись2,Запись2,Запись1):- !. % вставить факт обратно в базу знаний
запись_вставить(пусто):-!. запись_вставить(Запись):- asserta(мз(Запись)), !.
% сама сортировка
сортировка(ЗаписьВниз,ЗаписьНаверх):- % выбрать запись из базы знаний
retract(мз(Запись1)), % определить какую из записей передать вниз, % а какую возможно вставить в этом предикате
запись_выбрать(ЗаписьВниз,Запись1,ЗаписьВниз1,ЗаписьВставить1), % рекурсия сортировки вниз
сортировка(ЗаписьВниз1,Запись2), % определить какую запись вставить обратно в знания % а какую передать наверх
запись_выбрать(ЗаписьВставить1,Запись2,ЗаписьВставить,ЗаписьНаверх), % выбранную запись на вставление - вставляем
запись_вставить(ЗаписьВставить), !. % конец фактов - запомним последний
сортировка(Запись,пусто):- запись_вставить(Запись), !.
показать_мои_записи:- мз(Запись), nl,write(Запись), откат показать_мои_записи:-!. сортировка:- сортировка(пусто,Запись), запись_вставить(Запись), показать_мои_записи, !.
В базе знаний “проба.txt” содержатся факты в следующем виде и порядке: мз(моя_запись(1,"я",23)). мз(моя_запись(2,"ты",3)). мз(моя_запись(3,"он",2)). мз(моя_запись(4,"она",123)). мз(моя_запись(5,"они",223)). мз(моя_запись(6,"вы",213)). мз(моя_запись(7,"кто",23)). мз(моя_запись(8,"что",20)). мз(моя_запись(9,"где",13)). мз(моя_запись(10,"когда",12)). мз(моя_запись(1,"я",5)). мз(моя_запись(2,"ты",55)). мз(моя_запись(3,"он",24)). мз(моя_запись(4,"она",1)). мз(моя_запись(5,"они",223)). мз(моя_запись(6,"вы",33)). мз(моя_запись(7,"кто",44)). мз(моя_запись(8,"что",20)). мз(моя_запись(9,"где",113)). мз(моя_запись(10,"когда",4)).
Сначала нужно загрузить факты в память с помощью команды: Goal consult("проба.txt",мои_записи).
После этого можно запускать сортировку фактов: Goal сортировка. % отсортировать один раз
Надо заметить что сортировка за один раз не расставляет все факты полностью по возрастанию Значения факта: здесь предикат “сортировка” - это лишь одна итерация сортировки. Однако за одну итерацию сразу несколько фактов перемещаются на довольно длинное расстояние в списке фактов. После нескольких выполнений предиката “сортировка” факты будут полностью отсортированы. Дело в том, что чтобы оценить окончание сортировки нужно сделать дополнительный предикат, который бы перезапускал сортировку в случае не полной сортировки фактов. Вот результаты сортировки входных фактов из файла “проба”:
Итерация 1.
моя_запись(4,"она",1) моя_запись(2,"ты",3) моя_запись(3,"он",2) моя_запись(1,"я",23) моя_запись(4,"она",123) моя_запись(6,"вы",213) моя_запись(7,"кто",23) моя_запись(8,"что",20) моя_запись(9,"где",13) моя_запись(10,"когда",12) моя_запись(1,"я",5) моя_запись(2,"ты",55) моя_запись(3,"он",24) моя_запись(10,"когда",4) моя_запись(5,"они",223) моя_запись(6,"вы",33) моя_запись(7,"кто",44) моя_запись(8,"что",20) моя_запись(9,"где",113) моя_запись(5,"они",223)
Итерация 2.
моя_запись(4,"она",1) моя_запись(3,"он",2) моя_запись(2,"ты",3) моя_запись(10,"когда",4) моя_запись(1,"я",23) моя_запись(4,"она",123) моя_запись(7,"кто",23) моя_запись(8,"что",20) моя_запись(9,"где",13) моя_запись(10,"когда",12) моя_запись(1,"я",5) моя_запись(2,"ты",55) моя_запись(3,"он",24) моя_запись(8,"что",20) моя_запись(6,"вы",213) моя_запись(6,"вы",33) моя_запись(7,"кто",44) моя_запись(9,"где",113) моя_запись(5,"они",223) моя_запись(5,"они",223)
Итерация 3
моя_запись(4,"она",1) моя_запись(3,"он",2) моя_запись(2,"ты",3) моя_запись(10,"когда",4) моя_запись(1,"я",5) моя_запись(1,"я",23) моя_запись(7,"кто",23) моя_запись(8,"что",20) моя_запись(9,"где",13) моя_запись(10,"когда",12) моя_запись(8,"что",20) моя_запись(2,"ты",55) моя_запись(3,"он",24) моя_запись(6,"вы",33) моя_запись(4,"она",123) моя_запись(7,"кто",44) моя_запись(9,"где",113) моя_запись(6,"вы",213) моя_запись(5,"они",223) моя_запись(5,"они",223)
Итерация 4
моя_запись(4,"она",1) моя_запись(3,"он",2) моя_запись(2,"ты",3) моя_запись(10,"когда",4) моя_запись(1,"я",5) моя_запись(10,"когда",12) моя_запись(1,"я",23) моя_запись(8,"что",20) моя_запись(9,"где",13) моя_запись(8,"что",20) моя_запись(7,"кто",23) моя_запись(3,"он",24) моя_запись(6,"вы",33) моя_запись(7,"кто",44) моя_запись(2,"ты",55) моя_запись(9,"где",113) моя_запись(4,"она",123) моя_запись(6,"вы",213) моя_запись(5,"они",223) моя_запись(5,"они",223)
Итерация 5
моя_запись(4,"она",1) моя_запись(3,"он",2) моя_запись(2,"ты",3) моя_запись(10,"когда",4) моя_запись(1,"я",5) моя_запись(10,"когда",12) моя_запись(9,"где",13) моя_запись(8,"что",20) моя_запись(8,"что",20) моя_запись(1,"я",23) моя_запись(7,"кто",23) моя_запись(3,"он",24) моя_запись(6,"вы",33) моя_запись(7,"кто",44) моя_запись(2,"ты",55) моя_запись(9,"где",113) моя_запись(4,"она",123) моя_запись(6,"вы",213) моя_запись(5,"они",223) моя_запись(5,"они",223)
Как видно, на пятой итерации все факты полностью отсортированы.
Хотя можно было бы уже остановиться и на третьей итерации, ведь лучшие факты уже находились в начале базы знаний, а точность их сортировки не так и важна в данной задаче. Недостаток алгоритма в том, что если в фактах есть много записей с одинаковыми значениями, то сортировка каждый раз будет сдвигать такие факты на одно место вверх. А вот более сложный алгоритм. Здесь устранён недостаток, описанный выше. И теперь одинаковые записи сортируются как одна запись: если две записи равны, то они собираются в список и далее путешествуют по сортировке вместе. Если далее встретится еще равная запись, то и она присоединится к списку. Таким образом, сортировка производится за несколько итераций вне зависимости от количества одинаковых фактов.
% пузырьки легкие всплывают, а тяжелые тонут % а пузырьки одинаковые - цепляются к друг дружке
domainsИмяЗаписи = string НомерЗаписи, ЗначениеЗаписи = integer МояЗапись=моя_запись(НомерЗаписи, ИмяЗаписи, ЗначениеЗаписи); мои_записи(МоиЗаписи); пусто МоиЗаписи = МояЗапись*
database - мои_записи мз(МояЗапись)
predicates
показать_мои_записи значение_записи(МояЗапись,ЗначениеЗаписи) запись_выбрать(МояЗапись З1, МояЗапись З2, МояЗапись Вставить, МояЗапись Наверх) запись_вставить(МояЗапись) записи_вставить(МоиЗаписи) сортировка(МояЗапись Вниз, МояЗапись Вверх) - (i,o) сортировка запись_выбрать_вниз(МояЗапись, МояЗапись, МояЗапись Вниз, МояЗапись) запись_выбрать_вверх(МояЗапись, МояЗапись, МояЗапись, МояЗапись Вверх) записи_сложить(МояЗапись,МояЗапись,МояЗапись) - (i,i,o)
clauses
% сложить две записи с одинаковым значением
записи_сложить(Запись1,Запись2,мои_записи([Запись1,Запись2])):- !. % взять значение записи
значение_записи(моя_запись(_,_,Значение),Значение):-!. значение_записи(мои_записи([Запись|_]),Значение):-значение_записи(Запись,Значение),!.
% выбрать какую запись добавить, а какую передать далее
запись_выбрать(Запись1,Запись2,Запись1,Запись2):- значение_записи(Запись1,Значение1), значение_записи(Запись2,Значение2), Значение1Значение2, !. запись_выбрать(Запись1,Запись2,Запись2,Запись1):-!.
% если записи равны, то их обоих нужно собрать в список и тащить вниз
запись_выбрать_вниз(Запись1,Запись2,ЗаписьВниз,пусто):- значение_записи(Запись1,Значение1), значение_записи(Запись2,Значение2), Значение1=Значение2, записи_сложить(Запись1,Запись2,ЗаписьВниз), !. % если не равны, то обычное сравнение
запись_выбрать_вниз(пусто,Запись,Запись,пусто):-!.
запись_выбрать_вниз(Запись,пусто,Запись,пусто):-!. запись_выбрать_вниз(Запись1,Запись2,ЗаписьВниз,ЗаписьВверх):- запись_выбрать(Запись1,Запись2,ЗаписьВниз,ЗаписьВверх), !.
% если записи равны, то их обоих нужно собрать в список и тащить вверх
запись_выбрать_вверх(Запись1,Запись2,пусто,ЗаписьВверх):- значение_записи(Запись1,Значение1), значение_записи(Запись2,Значение2), Значение1=Значение2, записи_сложить(Запись1,Запись2,ЗаписьВверх), !. % если не равны, то обычное сравнение
запись_выбрать_вверх(Запись,пусто,пусто,Запись):-!. запись_выбрать_вверх(пусто,Запись,пусто,Запись):-!. запись_выбрать_вверх(Запись1,Запись2,ЗаписьВниз,ЗаписьВверх):- запись_выбрать(Запись1,Запись2,ЗаписьВниз,ЗаписьВверх), !.
% вставить список записей
записи_вставить([Запись|Записи]):- запись_вставить(Запись), записи_вставить(Записи), !. записи_вставить([]):-!.
% вставить запись или список записей
запись_вставить(пусто):-!. запись_вставить(мои_записи(Записи)):- записи_вставить(Записи), !. запись_вставить(Запись):- asserta(мз(Запись)), !.
% сама сортировка фактов
сортировка(ЗаписьВниз,ЗаписьНаверх):- % вытащить текущий факт из базы
retract(мз(Запись1)), % посмотреть, что далее вниз пойдет
запись_выбрать_вниз(ЗаписьВниз,Запись1,ЗаписьВниз1,ЗаписьВставить1), % вызвать рекурсию сортировки (продолжим далее)
сортировка(ЗаписьВниз1,ЗаписьНаверх1), % посмотреть, что вернуть наверх, а что положить в базу знаний
запись_выбрать_вверх(ЗаписьВставить1,ЗаписьНаверх1,ЗаписьВставить,ЗаписьНаверх), запись_вставить(ЗаписьВставить), !. % конец фактов - запомним последний
сортировка(Запись,пусто):- запись_вставить(Запись), !. % для показа записей на экран показать_мои_записи:- мз(Запись1), nl,write(Запись1), откат. показать_мои_записи:-!. % вызов сортировки
сортировка:- сортировка(пусто,Запись), запись_вставить(Запись), показать_мои_записи, % повторить, !. вот результаты сортировки: Итерация 1
Моя_запись(4,"она",1) моя_запись(2,"ты",3) моя_запись(3,"он",2) моя_запись(1,"я",23) моя_запись(4,"она",123) моя_запись(6,"вы",213) моя_запись(7,"кто",23) моя_запись(8,"что",20) моя_запись(9,"где",13) моя_запись(10,"когда",12) моя_запись(1,"я",5) моя_запись(2,"ты",55) моя_запись(3,"он",24) моя_запись(10,"когда",4) моя_запись(6,"вы",33) моя_запись(7,"кто",44) моя_запись(8,"что",20) моя_запись(9,"где",113) моя_запись(5,"они",223) моя_запись(5,"они",223) Итерация 2
моя_запись(4,"она",1) моя_запись(3,"он",2) моя_запись(2,"ты",3) моя_запись(10,"когда",4) моя_запись(1,"я",23) моя_запись(4,"она",123) моя_запись(7,"кто",23) моя_запись(8,"что",20) моя_запись(9,"где",13) моя_запись(10,"когда",12) моя_запись(1,"я",5) моя_запись(2,"ты",55) моя_запись(3,"он",24) моя_запись(8,"что",20) моя_запись(6,"вы",33) моя_запись(7,"кто",44) моя_запись(9,"где",113) моя_запись(6,"вы",213) моя_запись(5,"они",223) моя_запись(5,"они",223) Итерация 3
моя_запись(4,"она",1) моя_запись(3,"он",2) моя_запись(2,"ты",3) моя_запись(10,"когда",4) моя_запись(1,"я",5) моя_запись(1,"я",23) моя_запись(7,"кто",23) моя_запись(8,"что",20) моя_запись(9,"где",13) моя_запись(10,"когда",12) моя_запись(8,"что",20) моя_запись(2,"ты",55) моя_запись(3,"он",24) моя_запись(6,"вы",33) моя_запись(7,"кто",44) моя_запись(9,"где",113) моя_запись(4,"она",123) моя_запись(6,"вы",213) моя_запись(5,"они",223) моя_запись(5,"они",223) Итерация 4
моя_запись(4,"она",1) моя_запись(3,"он",2) моя_запись(2,"ты",3) моя_запись(10,"когда",4) моя_запись(1,"я",5) моя_запись(10,"когда",12) моя_запись(8,"что",20) моя_запись(9,"где",13) моя_запись(8,"что",20) моя_запись(7,"кто",23) моя_запись(1,"я",23) моя_запись(3,"он",24) моя_запись(6,"вы",33) моя_запись(7,"кто",44) моя_запись(2,"ты",55) моя_запись(9,"где",113) моя_запись(4,"она",123) моя_запись(6,"вы",213) моя_запись(5,"они",223) моя_запись(5,"они",223) Итерация 5
моя_запись(4,"она",1) моя_запись(3,"он",2) моя_запись(2,"ты",3) моя_запись(10,"когда",4) моя_запись(1,"я",5) моя_запись(10,"когда",12) моя_запись(9,"где",13) моя_запись(8,"что",20) моя_запись(8,"что",20) моя_запись(1,"я",23) моя_запись(7,"кто",23) моя_запись(3,"он",24) моя_запись(6,"вы",33) моя_запись(7,"кто",44) моя_запись(2,"ты",55) моя_запись(9,"где",113) моя_запись(4,"она",123) моя_запись(6,"вы",213) моя_запись(5,"они",223) моя_запись(5,"они",223) %
Вообще, есть классическая сортировка с помощью бинарных деревьев.
Такая сортировка работает быстрее описанного выше метода. Но ее недостаток в том, что она выполняет полную сортировку до полного упорядочивания всех элементов списка. А предложенная мной сортировка делается не полностью, лишь увеличивая вероятность появления нужного факта в начале базы фактов ПРОЛОГа Мною была проведена тестовая оценка классической сортировки и предложенной: Так для количества записей 100 в базе, классическая сортировка делает 800 сравнений, а предложенная в статье (за два прохода): 378. Для 400 записей, соответственно: 11600 и 1500 (за два прохода). Однако если учесть, что время на выполнение одного сравнения в предложенном методе уходит больше и количество проходов при увеличении записей возрастает, выгодность классического метода увеличивается. Вот классический пример сортировки на ПРОЛОГе:
========================= % сортировка с использованием Reference Domains % То есть когда значение предает как ссылка
% файл пример находится в ch11e04.pro к VIP5.5 % и показывает как использовать ссылочные значения % в классической сортировке по методу бинарного дерева
/* Program ch11e05.pro */
DOMAINS
tree = reference t(val, tree, tree) val = integer list = integer*
PREDICATES
insert(integer,tree) instree(list,tree) nondeterm treemembers(integer,tree) sort(list,list)
CLAUSES
insert(Val,t(Val,_,_)):-!. insert(Val,t(Val1,Tree,_)):- Val>Val1, !, insert(Val,Tree).
insert(Val,t(_,_,Tree)):- insert(Val,Tree).
instree([],_). instree([H|T],Tree):- insert(H,Tree), instree(T,Tree).
treemembers(_,T):- free(T), !, fail.
treemembers(X,t(_,L,_)):- treemembers(X,L).
treemembers(X,t(Refstr,_,_)):- X = Refstr.
treemembers(X,t(_,_,R)):- treemembers(X,R).
sort(L,L1):- % рассортировывает элементы списка в бинарное дерево
instree(L,Tree), % преобразовывает бинарное дерево обратно в список
findall(X,treemembers(X,Tree),L1).
GOAL
sort([3,6,1,4,5],L), write("L=",L),nl.
% Здесь значения-ссылки используются только в домайне tree
Промежуточные итоги
Итак, две ведущие технологии построения распределенных объектных сред имеют сходные базовые принципы и множество различий в деталях реализации. Обе технологии имеют солидный багаж проектов на их основе, что наглядно демонстрируют многочисленные "истории успеха" на Web-узле консорциума OMG () и домашней страничке СОМ (). Примеры конкретных реализаций систем на базе CORBA группируются по отраслям промышленности, и их список очень внушителен - аэрокосмическая индустрия, банковское дело и финансы, химическая промышленность, здравоохранение, производство, издательские компании, розничная торговля, телекоммуникации, правительственные и научные организации и, наконец, реклама и маркетинг.
СОМ также может похвастаться значительным числом инсталляций. Однако до недавнего времени в ее епархию входили преимущественно настольные системы и сети масштаба рабочей группы или подразделения. Подобные СОМ-приложения доказали свою надежность и эффективность. Дополнительный плюс - интеграция с языками программирования и инструментальными средствами, которая упрощает разработку приложений на базе СОМ. Без Windows-систем сейчас не обходится большинство предприятий, поэтому СОМ/DСОМ неизбежно будет важным элементом корпоративных архитектур. Вопрос в том, сможет ли эта технология взять на себя сложные приложения корпоративного масштаба, как это делает CORBA (для чего она, собственно, и создавалась).
Построение распределенных объектных систем - не только организация вызовов удаленных методов объектов. Необходимо искать эффективное решение таких проблем, как развертывание, обеспечение защиты, управление транзакциями и координированное использование разделяемых ресурсов, обработка исключительных и ошибочных ситуаций, поддержка асинхронных коммуникаций и обеспечение высокой производительности. СОМ прошла серьезный путь от поддержки составных документов к распределенным объектам. Теперь ее успех как технологии корпоративного масштаба зависит от того, насколько эффективными будут усилия Microsoft в решении перечисленных выше задач.
Отсутствие четкой формализации архитектуры, ориентация на оптимизацию под отдельный язык или платформу, а не на общие решения, типичный для корпорации процесс внесения изменений по принципу - все это аргументы не в пользу СОМ. С другой стороны, у СОМ, безусловно, есть серьезные заделы, позволяющие рассчитывать на успех. Сервер транзакций MTS способен значительно повысить продуктивность клиент-серверных приложений. Полная интеграция MTS и службы асинхронных взаимодействий MSMQ с базовыми возможностями СОМ в спецификации СОМ+, а также средства поддержки унаследованных приложений на мэйнфреймах и тесная взаимосвязь СОМ и ее служб с операционной системой делают эту модель привлекательной базовой технологией для построения объектно-ориентированных распределенных приложений. Но только для тех вычислительных сред, которые опираются на Windows. Серверные технологии Microsoft готовы поддержать ее союзники. Имеющая огромное влияние на корпоративный рынок Compaq в феврале сообщила о запуске целой серии программ и служб, цель которых - обеспечить крупным предприятиям максимально благоприятные условия для развертывания архитектуры Distributed interNet Applications на платформе NT. По сравнению с СОМ, CORBA представляет собой четкую и полную объектную архитектуру, изначально ориентированную на гетерогенную среду. Использование IDL для всех определений элементов архитектуры делает модель согласованной, четко организованной и легко расширяемой. Концепция отображения в языки программирования обеспечивает взаимодействие объектов, создаваемых в разных языковых средах. Понятие объектной ссылки обеспечивает строгую идентификацию объекта и упрощает работу по размещению объекта. CORBA обеспечивает реальную многоплатформенность. Реализации CORBA многочисленны и принадлежат множеству производителей (с их полным списком и описанием продуктов можно познакомиться в Web по адресу ). Эти продукты поддерживают обширный диапазон аппаратных платформ, в том числе мэйнфреймы, миникомпьютеры и Unix-системы.Однако разнообразие реализаций имеет и свои недостатки, прежде всего потенциальную проблему несовместимости. Ряд продуктов позволяет сосуществовать объектам СОМ/CORBA. Взаимодействие объектов CORBA с OLE/COM определяется в спецификации CORBA, начиная с версии 2.0. Поддержку смешанной среды СОМ/CORBA обеспечивают в своих системах, например, компании Iona, Visual Edge и NobleNet. Так, Iona получила лицензию от Microsoft на использование технологии СОМ в системе СОМet, которая позволяет организовать "мост" между объектами в разных архитектурах. Непосредственную интеграцию СОМ, CORBA, RPC и Java обеспечивает анонсированная в начале этого года последняя версия системы Nouveau компании NobleNet.
Проверка целостности сегментов, формата и грамматики
Данные действия выполняются по окончании перевода и имеют своей целью проверить, все ли сегменты остались на своих местах, сохранилась ли форматирующая информация, и корректен ли результирующий текст с точки зрения грамматики целевого языка.
Среди перечисленных технологий наибольший интерес представляют терминологические словари и память переводов, поскольку именно от их эффективности зависит скорость и качество перевода. Технология построения терминологических словарей достаточно хорошо проработана и основана на принципах, аналогичных тем, что применяются в обычных двуязычных словарях. Разбиение текста на термины обычно осуществляется по пробелам с дополнительным привлечением некоторого морфологического анализа.
Сложнее обстоит дело с организацией памяти переводов. Наряду с тривиальной задачей поиска языковой пары, включающей сегмент, идентичный заданному, память переводов должна обеспечивать возможность поиска сегментов, похожих на данный по некоторому критерию. Таким образом, центральной проблемой классической памяти переводов является построение анализатора таких "нечетких совпадений" (fuzzymatches), характеристики которого и определяют преимущества и недостатки каждой конкретной системы профессионального перевода.
Проверка соответствия терминологии
После того, как перевод выполнен, компьютер осуществляет проверку того, что все вхождения каждого из терминов были переведены одинаково. Например, если термин "операционная система" был заменен при своем первом вхождении на "operatingsystem", а при втором вхождении на "operationalsystem", то должно быть выдано соответствующее предупреждении о нарушении единства терминологии.
Пути расширения возможностей
Поскольку функцией памяти переводов является поиск в базе данных переведенных фрагментов заданного сегмента, то пределом ее возможностей является, очевидно, выборка, максимально покрывающая исходный сегмент и не содержащая никакой избыточной (лишней) информации.
Попытаемся выделить возможные варианты повышения качества памяти переводов, воспользовавшись приведенным ранее примером. Выберем и рассмотрим две языковые пары: таблица 4.
Таблица 4
| Языковая пара 1 | Температура регулируется поворотом ручки по часовой стрелке |
| The temperature can be adjusted by turning the knob clockwise | |
| Языковая пара 2 | Напор воды регулируется поворотом ручки по часовой стрелке |
| The water head can be adjusted by turning the knob clockwise |
Сходство сегментов на исходном языке позволяет сделать предположение, что их переводы, то есть сегменты на целевом языке также должны быть похожи. Коль скоро это так, что возникает резонное желание выделить из двух приведенных языковых пар общую часть и представить ее в виде новой языковой пары. Выполнив несложную операцию пересечения строк, получаем следующий результат: таблица 5.
Таблица 5
| Языковая пара 3 | Регулируется поворотом ручки по часовой стрелке |
| can be adjusted by turning the knob clockwise |
Теперь для любого сегмента, включающего фрагмент " регулируется поворотом ручки по часовой стрелке", может быть выбрана языковая пара номер 3, содержащая только необходимый перевод для фрагмента.
Однако, не всегда все так хорошо. Чуть более внимательный взгляд на этот пример сразу же заставит нас признать, что создание таких "укороченных" языковых пар эквивалентно уменьшению размера сегмента, а мы помним, чем это грозит. Маленький фрагмент текста, в особенности, если он не ограничен никакими знаками препинания, едва ли может быть правильно переведен без учета контекста. Следовательно, при выделении общих частей в двух используемых уже языковых парах необходимо руководствоваться теми же принципами, что и при начальной сегментации исходного текста.
К тому же, не стоит забывать, что пересечение сегментов на исходном языке не обязательно изоморфно пересечению сегментов на целевом языке. Это связано с различиями правил грамматики в разных языках, порядка слов, соответствия слов понятиям. Поэтому осмысленное значение целевого сегмента языковой пары, образованной пересечением, можно ожидать только при: значительном размере обоих сегментов вновь образованной языковой пары; эвристически определенном изоморфизме пересечения сегментов на исходном и целевом языке (например, если пересечение осуществлено по знакам пунктуации); морфологическом и синтаксическом анализе результата пересечения с привлечением технологии машинного перевода.
Еще одной немаловажной задачей при реализации механизма описанных манипуляций с языковыми парами является создание некоторого формализма, позволяющего однозначно определить, какие именно пары должны подвергаться обработке, как именно должен формироваться результат, как должен осуществляться поиск сегмента и каковы критерии сравнения сегментов при поиске. Этим мы теперь и займемся.
Qa_7.shtml
Delphi, С++Builder и COM: вопросы и ответы
Наталия Елманова
Компьютер Пресс - CD, 1999, N 7
Copyright N.Elmanova & ComputerPress Magazine.
После публикации осенью 1998 г. цикла статей, посвященных C++Builder и COM-технологии, в адрес редакции поступило много вопросов, связанных с проблемами использования COM в приложениях Delphi и C++Builder. Данная статья посвящена ответам на некоторые наиболее часто встречающиеся из них.
Уважаемая Наталия! Я только начал изучать Delphi и не могу решить простые задачи, например, такие как инсталляция новых компонент *.ocx ("Компьютер Пресс CD, 1999, N 3).
Не могли бы Вы помочь в решении этих вопросов?
Установка ActiveX (OCX) в палитру компонентов осуществляется просто: из меню среды разработки нужно выбрать опцию "Component/Import ActiveX Control". Если в полученном списке нужного элемента не окажется, нужно перед этим его зарегистрировать из командной строки: Regsvr32 <имя *.ocx-файла>
В документации к Delphi и C++Builder установка элементов управления ActiveX описана довольно подробно.
Уважаемый автор,
Не могли бы Вы подробнее осветить вопрос применения созданных компонентов ActiveX в оболочке Microsoft Word. Процесс создания объекта ActiveX не вызывает столько вопросов, сколько вызывает вопросов проблема его распространения. Как среда внедрения заманчиво выглядит Microsoft Word, в связи с его большей распространенностью. Но созданные компоненты ActiveX не доступны во "вставляемых" объектах Word`а. Буду Вам очень признателен, если вы подскажете пути решения этой проблемы.
Если имеются в виду объекты, вставляемые с помощью пункта меню Word "Вставка/Объект", то обычно таким образом вставляются OLE-объекты, поддерживаемые так называемыми серверами документов. Элементы ActiveX могут и не являться такими серверами. Тем не менее, их можно вставить непосредственно в документ Word 97, используя опцию "Элементы управления" панели инструментов Visual Basic. На диалоговой панели "Элементы управления" следует нажать кнопку "Дополнительные элементы" и выбрать нужный элемент ActiveX.
Он должен присутствовать в списке, если он зарегистрирован. Если же нет, его можно зарегистрировать, выбрав опцию "Зарегистрировать элемент управления".
Помимо этого, практически любой ActiveX можно поместить на форму Visual Basic, вызываемую из документа Word. Однако следует заметить, что, если Вы отдаете документ для использования на другом компьютере, следует отдать и библиотеку, содержащую элемент ActiveX - документ Word содержит лишь ссылку на нее (и организовать ее регистрацию). Иными словами, в данном случае мы имеем дело с типичной задачей поставки приложения (или документа - в данном случае это неважно), содержащего библиотеку ActiveX. Ее можно решить, создав обычный дистрибутив (хотя бы с помощью InstallShield Express). Однако более корректным кажется использование для этой цели Internet Explorer , так как он, в отличие от Word, предусматривает автоматическую регистрацию элементов управления ActiveX в составе Web-страницы. После создания и переноса CAB-файла и Web-страницы на Web-сервер эта страница в браузере открывается, но на месте предполагаемой активной формы появляется только квадратик. Разъясните, в чем может быть проблема
Причин такого поведения может быть несколько. Первая причина связана с тем, что далеко не все браузеры поддерживают отображение ActiveX с помощью тега<OBJECT>. Для отображения ActiveX следует использовать MS Internet Explorer версии 3.0 и выше (отметим, что в комплект поставки некоторых 32-разрядных версий Windows входит более ранняя версия этого браузера) либо Netscape Communicator, оснащенный соответствующим модулем расширения (plug-in). Дело в том, что Netscape Communicator позиционирует себя на рынке как многоплатформенный браузер, поэтому сам по себе он не отображает элементов управления ActiveX, так как ActiveX есть технология, специфичная для Windows.
Вторая причина может быть связана с настройкой уровня безопасности браузера. Пользователь, желающий выполнять элемент управления ActiveX под управлением браузера, должен в общем случае дать разрешение на это - ведь ActiveX содержит исполняемый код, и в общем случае нет никакой гарантии, что он безопасен в использовании.
Поэтому, если элемент управления ActiveX не имеет электронной подписи (а в России сейчас получить ее довольно сложно), при использовании настроек браузера по умолчанию он выполняться не будет. При этом некоторые версии Internet Explorer не только не сгружают ActiveX и тем более не выполняют его, но при этом еще и ничего не сообщают пользователю. Чтобы тем не менее осуществить выполнение неподписанного элемента управления ActiveX, в настройках параметров безопасности браузера нужно явным образом указать, что пользователь разрешает выполнять код в элементах управления ActiveX, полученных либо с конкретного Web-сервера, либо с любого сервера в Internet.
Есть и третья возможная причина - настройки операционной системы компьютера пользователя могут быть таковы, что пользователю запрещено изменять реестр, и в этом случае ActiveX в нем, естественно, не зарегистрируется.
И, наконец, еще одна возможная причина может заключаться в том, что приложение может быть разбито на "пакеты" (packages), которые ошибочно не включены в комплект поставки. В этом случае рекомендуется проверить опции проекта и, если необходимо, добавить недостающие файлы. С удовольствием прочитал вашу статью: "Создание контроллеров автоматизации....", но по ходу дела у меня возник ряд вопросов: Как заставить управляемое приложение остаться активным после завершения контроллера. Пример: некая программа генерирует отчет, управляя редактором Word. Требуется, чтобы после того как отчет создан, окно Word не закрывалось. Я добился этого методом вызова функции AddRef применительно к управляемому объекту, но подозреваю, что этот способ не корректен.
В принципе можно использовать вызов функции AddRef. Но наиболее принятый способ (если используются вариантные переменные, как в примерах из статьи "Создание контроллеров автоматизации...") - поместить вариантную переменную в глобальную область видимости приложения-контроллера. В этом случае данные, содержащиеся в этой переменной, могут существовать, пока запущено приложение-контроллер, а вместе с ними остается активным и сам COM-сервер (если, конечно, из приложения-контроллера не был вызван метод, приводящий к его закрытию, и если этой вариантной переменной не было присвоено другое значение). Я не понял, как формируется имя сервера, занесенное в реестр (Project1.MyAuto3)? MyAuto3 - мы задаем явно, а откуда берется Project1???
Project1 в данном случае есть имя исполняемого файла COM-сервера.
MyAuto3 - это имя COM-объекта, реализованного в данном сервере (COM-объектов в одном сервере может быть и несколько). Мой вопрос связан с автоматизацией Excel из приложений Delphi. Например, вполне нормально выполняется код, написанный в Delphi:
var v:variant; begin v := CreateOleObject('Excel.Application.8'); v.Visible:= True; v.WorkBooks.Add; v.Range('A2') := 12; v.ActiveCell.FormulaR1C1 := '=RAND()'; v.ActiveCell.Font.Bold := True; end;
Почему при этом не выполняется команда:
v.Range('A2').Select;
При этом появляется сообщение об ошибке: Member not found. Точно так же не выполняются и многие другие команды, которые можно найти в макросах Excel.
Я экспериментировал с Visual FoxPro 5.0, и все команды (макросы) из Excel можно переносить в него практически без изменений, подставляя впереди имя переменной, например v.Range('A2').Select На самом деле в Delphi подобная команда выглядит так:
v.Range['A2'].Select;.
Иными словами, если Вы пользуетесь справкой по Visual Basic for Applications, нужно менять в содержащихся в ней примерах не только кавычки, но и скобки. Дело в том, что получающийся код должен удовлетворять требованиям синтаксиса языка программирования того средства разработки, на котором пишется контроллер Excel. Хотя синтаксис Pascal и позволяет создавать видимость того, что мы вызываем методы вариантной переменной (не все языки программирования позволяют это делать, например, в C++ так с вариантными переменными обращаться нельзя), из этого не следует, что в него можно включать синтаксические конструкции из Visual Basic без изменений. Что касается FoxPro - синтаксис используемого в этом средстве разработки языка с этой точки зрения (я имею в виду именно употребление скобок и кавычек в описании методов переменных, содержащих ссылки на COM-объекты), видимо, более близок к Visual Basic, чем синтаксис Pascal. Чем с точки зрения синтаксиса может при автоматизации Excel помочь импорт библиотеки типов?
Если рассматривать только проблемы синтаксиса, импорт библиотеки типов полезен, скорее, в случае С++, а не Pascal.
Если мы не импортируем библиотеку типов, то синтаксис С++ будет совсем другим, нежели синтаксис Pascal. Рассмотрим простейший пример: 1) Form1.Show - этот оператор использует настоящий метод класса TForm (аналог на C++ - Form1->Show()); 2) Var V:variant; V:=CreateOleObject('Excel.Application'); ..... V.Visible:=True; -
Здесь используется "метод" для установки "свойства" варианта, но в действительности это инициирование вызова удаленных процедур в Excel (и его внутренних методов). В данном случае внутренний метод Excel, предназначенный для показа его окна, может называться как угодно, и "Show" есть лишь внешнее опубликованное имя этого внутреннего метода. Аналог на C++ : Variant V; V=CreateOleObject("Excel.Application"); V.OlePropertySet("Visible",true); //!
Итак, мы видим, что на самом деле "Visible" с точки зрения C++ - это просто строка. Иными словами, и Visual Basic, и Delphi, и Visual FoxPro просто совершают некоторые манипуляции со строками, позволяя помещать их в исходный текст без явного указания, что это строки, и тем самым заставляя думать, что мы вызываем методы вариантной переменной. C++ таких вещей делать не позволяет. Зато его код иллюстрирует, что происходит на самом деле при автоматизации Excel в Visual Basic или Delphi. Фактически "Visible" - просто строка, передаваемая в Excel из приложения-контроллера. Импорт же библиотеки типов позволяет создать объекты в адресном пространстве контроллера автоматизации, имеющие те же методы, что и объекты в адресном пространстве Excel. Соответственно можно вызывать настоящие методы этого "своего" объекта, а их реализация на самом деле будет заключаться в вызове удаленных процедур, обращенных к Excel (даже если это локальный Excel), которые инициируют манипуляции уже с внутренними объектами Excel. Соответственно после этого синтаксис на любом языке будет похож (с точностью до скобок, кавычек и указателей) на синтаксис Visual Basic.
То есть код С++ V.Visible=true становится верным.
Правда, при использовании импорта библиотеки типов можно уже на этапе компиляции проверить, нет ли синтаксических ошибок в названии самих методов, и при этом само приложение-контроллер будет работать быстрее (за счет несколько иного механизма создания таблицы виртуальных методов). Но, если при этом используется раннее связывание, скорее всего, при этом приложение-контроллер окажется полностью несовместимым со старыми (или будущими) версиями Excel, так как даже при наличии тех же самых методов они окажутся в других местах таблицы виртуальных методов. Есть ли возможность с помощью Delphi или C++Builder создать контроллер автоматизации одновременно для Excel 7 и Excel 97?
Если нужно создать приложение-контроллер, совместимое и с текущей, и с прежней версиями Excel, лучше или не импортировать библиотеку типов, или импортировать, но использовать позднее связывание по изложенным выше причинам (в документации к Delphi подробно описано, как это сделать), и не использовать вызовы методов, отсутствующих в старой версии Excel.
Совместимость со старыми версиями COM-серверов есть требование спецификации COM, и надо полагать, Microsoft следует своей собственной спецификации.
Однако не стоит полагаться на это, не произведя соответствующего тестирования с теми версиями COM-сервера, с которыми предполагается использовать данный контроллер. Дело в том, что в Office 95 в разных языковых версиях (немецкой, французской, английской) некоторые методы назывались по-разному, и с Delphi 2 поставлялся пример, который это иллюстрировал. Поэтому стоит уточнить (или проверить экспериментально), как именно с точки зрения именования методов Excel как COM-сервера локализована версия, которую планируется использовать.
Qa_8.shtml
Delphi, С++Builder и базы данных: вопросы и ответы
Наталия Елманова
Компьютер Пресс - CD, 1999, N 8
Copyright N.Elmanova & ComputerPress Magazine.
После публикации в 1997-98 гг. цикла статей, посвященных C++Builder, в адрес редакции поступило много вопросов, связанных с проблемами использования баз данных в приложениях Delphi и C++Builder. Данная статья посвящена ответам на некоторые наиболее часто встречающиеся из них.
В статье "Создание серверов приложений с помощью Delphi 3" вы написали, что подключались к Personal Oracle с помощью BDE. Я очень прошу вас рассказать, как вы это сделали. Для меня пока это остается загадкой.
Доступ к Personаl Oracle (как и к любой другой версии этой СУБД) осуществляется следующим образом.
Сначала нужно запустить сервер (в случае Personal Oracle для Windows 95 это отдельное приложение, в случае Oracle для Windows NT - набор сервисов, обслуживающих конкретную базу данных) и настроить клиентскую часть Oracle. Для этого следует запустить утилиту SQLNet Easy configuration (в случае Oracle 8 - Oracle Net8 Easy Config) и с ее помощью создать описание псевдонима базы данных Oracle (для него, как и в BDE, используется термин alias, но это не то же самое, что псевдоним BDE). При создании этого описания важны три параметра. Первый из них - сетевой протокол, с помощью которого осуществляется доступ к серверу Oracle (IPX/SPX, TCP/IP и др.). Второй параметр - местоположение сервера в сети. В случае Personal Oracle это обычно компьютер с IP-адресом 127.0.0.1 (это специальный адрес для доступа к локальному компьютеру, так называемый TCP loopback address). Третий параметр - имя базы данных. По умолчанию в случае Personal Oracle она называется ORCL. В общем случае имя может быть любым, но это должно быть имя уже существующей базы данных, с которой вы собираетесь работать. В принципе все описания псевдонимов Oracle хранятся в текстовом файле TNSNAMES.ORA, и можно редактировать его вручную.
Далее следует запустить утилиту SQL Plus и проверить соединение клиента с сервером.
Обычно в качестве имени пользователя используется имя SYSTEM и пароль MANAGER (если вы сами администрируете сервер). Если же сервер был установлен раньше, есть смысл узнать у администратора базы данных, каким именем и паролем следует воспользоваться. Помимо имени пользователя и пароля, SQL Plus запросит так называемую строку связи, в которой должно содержаться имя сервиса, который был создан вами перед этим. При удачном соединении в SQL Plus появится соответствующее сообщение. Отметим, что утилита Oracle Net8 Easy Config позволяет протестировать соединение непосредственно в процессе создания описания сервиса. Если соединение с сервером было неудачным, стоит проверить, поддерживается ли указанный сетевой протокол и виден ли в сети компьютер, на котором установлен сервер, и, если нужно, внести изменения в описание сервиса.
Далее можно, наконец, заняться настройкой BDE. В качестве Server Name следует указать имя псевдонима Oracle (его можно просто выбрать из выпадающего списка, так как BDE Administrator также обращается к файлу TNSNAMES.ORA). После этого нужно проверить соединение с сервером через BDE с помощью BDE Administrator или SQL Explorer.
Если соединение не устанавливается и появляется сообщение "Vendor initialization failed", стоит убедиться, что динамическая загружаемая библиотека, указанная в параметре Vendor Init драйвера Oracle, действительно присутствует на данном компьютере. На всякий случай стоит скопировать ее в Windows\System, так как некоторые ранние версии BDE в Windows 95 не находят эту библиотеку в подкаталоге Bin каталога, в котором установлен клиент Oracle, в силу ограничений, налагаемых этой операционной системой на длину переменной окружения PATH. Отметим также, что при использовании Oracle 8 следует использовать версию не ниже 8.0.4; в случае использования более ранней версии следует обновить ее до 8.0.4. Недавно я перешел на использование Oracle, и все мои попытки использовать компонент TStoredProc кончаются неудачей. Почему?
Причины неработоспособности компонента TStoredProc могут быть следующими.
Во-первых, при использовании ODBC- доступа может оказаться, что применяемый вами ODBC-драйвер не поддерживает хранимые процедуры (как известно, не все ODBC-драйверы их поддерживают).
И во-вторых, имеется известная проблема, описание которой содержится в разделе Developers support корпоративного сайта Inprise. Дело в том, что число параметров хранимой процедуры, с которой взаимодействует компонент TStoredProc, не должно превышать 10. В случае, если реальное число параметров превышает 10, многие разработчики переписывают хранимые процедуры так, чтобы они использовали строковые параметры, содержащие по несколько реальных параметров. Есть ли возможность в Delphi как-то корректно прервать выполнение SQL запроса к серверу Oracle с помощью BDE? Например, при использованиис SQL Plus после отправки на выполнение SQL-запроса на экране появляется окно с кнопкой Cancel, благодаря чему мы имеем возможность в любой момент прервать выполнение этого запроса. Можно ли что-то подобное сделать в Delphi?
Насколько мне известно, для этой цели лучше всего использовать функции Oracle Call Interface (низкоуровневый API Oracle). В комплекте поставки Oracle есть соответствующие примеры для C, и переписать их на Pascal несложно.
Некоторые драйверы SQL Link позволяют прекратить выполнение запроса, если время его выполнения превышает заранее заданное значение (параметр MAX QUERY TIME соответствующего драйвера). Однако драйвер ORACLE, к сожалению, не входит в их число. Что необходимо предпринять, чтобы сгенерировать из ERwin таблицы для локальной базы данных Paradox 5.0? На компьютере установлены Delphi 4.0 и MetaBase.
Для этого требуется установить ODBC-драйвер для этой версии Paradox той же разрядности, что и ERwin. Затем нужно описать соответствующий ODBC-источник, и он будет доступен в ERwin. Не могли бы Вы мне подсказать, как заблокировать функцию вставки записи непосредственно в компоненте TDBGrid с сохранением всех остальных возможностей редактирования таблицы.
Наиболее разумным представляется создать обработчик события BeforeInsert компонента TTable, TQuery или TClientDataSet, данные из которых отображаются в TDBGrid.
Сам компонент TDBGrid не имеет подходящего события для обработки, так как это компонент, предназначенный только для создания пользовательского интерфейса, а в данном случае следует, по существу, запретить добавление записей в таблицу.
У меня в комплект Borland C++ Builder не входит Visual Query Builder. Могу ли я связать две таблицы без него?
Безусловно, можно связать две таблицы и без VQB. Самый простой способ - запустить Database Form Wizard и связать две таблицы, используя TQuery. Те два запроса, которые при этом получатся (один из них - параметризованный), можно использовать как образец.
Кроме того, можно просто написать вручную необходимый запрос к любому числу таблиц и поместить его в свойство SQL компонента TQuery. Все инструменты для генерации запросов (Visual Query Builder, SQL Builder и др.) просто предоставляют для этого визуальные средства, а результатом их работы является именно текст запроса, помещаемый в это свойство. Я установил Borland C++ Builder 3.0 Client/Server Suite и InterBase Server 5.1.1. (автоматически с ним установился InterBase 5.x Driver by Visigenic). Но у меня не работают хранимые процедуры. То есть процедура правильно откомпилирована, и вызов ее из C++ Builder осуществляется с помощью выполнения оператора
StoredProc1->ExecProc();
При этом возникает следующая ошибка : "Capability not supported. General SQL error. [Visigenic][ODBC InterBase 4.x Driver] Driver not capable".
ODBC-драйвер может не поддерживать хранимые процедуры. В этом случае стоит попытаться использовать драйвер SQL Link (он должен быть в C++ Builder 3.0 Client/Server Suite). Для этого нужно создать для вашей базы данных псевдоним типа INTRBASE. В этом случае хранимые процедуры должны работать.
Если хранимые процедуры тем не менее остаются недоступными, стоит проверить, что и в какой последовательности было установлено на ваш компьютер. Такие неприятности могут быть, если, например, вы установили какой-либо продукт, написанный на Delphi 2, после C++Builder 3.
В этом случае можно переустановить BDE, взяв его последнюю версию на сайте Inprise- все зарегистрированные пользователи C++ Builder 3.0 Client/Server Suite имеют право это сделать. При удалении записей из таблицы dBase с помощью компонента TTable они просто приобретают признак удаления, и я никак не могу добиться их физического удаления. Как быть?
Ваша проблема решается просто - для физического удаления записей нужно использовать функцию DbiPackTable (ее описание есть в справочном файле BDE). При добавлении новых записей с помощью TTable.AppendRecord в индексированную таблицу FoxPro через какое-то время (то есть при добавлении сразу большого количества записей) возникает ошибка: "Access to table disabled because of previous error. Read failure. File" <имя_файла.cdx>..
Возможно, причина заключается в том, что операции чтения-записи в файл, содержащий таблицу FoxPro, особенно при использовании кэширования, предоставляемого операционной системой, конфликтуют с содержимым индексного файла (это часто происходит при многопользовательской работе). Дело в том, что ранние версии dBase, FoxPro, Clipper работали с неподдерживаемыми индексами, то есть индексные файлы не обновлялись одновременно с таблицей, и для их синхронизации требовалось выполнять специальные операции. Но соответствующие средства разработки, применяемые в то время, обычно не поддерживали никаких аналогов транзакций - записи обычно вставлялись по одной.
В случае применения старых версий формата FoxPro следует избегать кэширования при выполнении дисковых операций с файловым сервером, содержащим базу данных FoxPro. Кроме того, следует проверить и, если необходимо, изменить в настройках BDE параметры MINBUFSIZE, MAXBUFSIZE, LOCAL SHARE - возможно, проблема заключается в недостаточной величине буферов BDE для кэширования данных или в одновременном доступе к данным приложений, использующих и не использующих BDE.
Еще одним из способов решения этой проблемы (самым радикальным) является замена FoxPro на какую-нибудь из серверных СУБД.
Например, IB Database неплохо справляется с одновременным вводом большого количества записей благодаря некоторым специфическим особенностям архитектуры этого сервера. Позволяет ли QuickReport выгружать данные в формате Microsoft Excel?
Quick Report не позволяет выгружать данные в формате Microsoft Excel. Но последние его версии позволяют сохранять отчеты в формате CSV (Comma Separated Value) и HTML, и оба эти формата можно прочесть с помощью Excel.
Помимо этого, для генерации отчета можно использовать автоматизацию Excel, вообще не прибегая к использованию QuickReport. Как можно создать свою форму просмотра отчетов QuickReport в С++Builder?
Для создания собственных окон просмотра отчета можно использовать компонент TQRPreview. Для этой цели следует создать форму (назовем ее PreviewForm), поместить на нее компонент TQRPreview, сослаться на нее в форме, содержащей отчет, и в форме, из которой вызывается просмотр отчета. Код для показа отчета выгладит примерно так: void __fastcall TForm1::Button1Click(TObject *Sender) { PreviewForm->Show(); QuickReport1->Preview(); }
Далее создадим обработчик события OnPreview компонента TQuickRep: void __fastcall TQuickReport1::QuickReport1Preview(TObject *Sender) { PreviewForm->QRPreview1->QRPrinter = QuickReport1->QRPrinter; }
После этого данный отчет будет появляться не в стандартном окне просмотра, а в форме PreviewForm. Возможно ли использование компонентов Decision Support System при генерации отчетов в QuickReport и, если можно , то каким образом? Если QuickReport не подходит для этих целей, то какие другие варианты Вы можете посоветовать?
Самый простой способ - использовать компоненты TQRLabel, текст в которых динамически меняется во время печати (то есть способ, которым можно напечатать все, что угодно, написав при этом немного кода). В принципе можно двумерное сечение куба записать во временную таблицу или в компонент TClientDataSet, написав соответствующий цикл, и сделать отчет на ее основе. Использование DecisionQuery в качестве источника данных для отчета также вполне возможно.
Другие возможные варианты - это использование автоматизации Word или Excel, либо вычисление сумм внутри отчета. Можно также использовать другие генераторы отчетов - например, с помощью Crystal Reports можно создавать отчеты, содержащие кросс-таблицы. Как корректно подключить Crystal Reports к Delphi ?
В составе Crystal Reports Professional имеется VCL-компонент для Delphi, элемент управления ActiveX, модуль CRPE32.PAS, котором объявлены все функции и структуры Print Engine API, и описание опубликованных методов Crystal Reports как сервера автоматизации. Соответственно есть следующие возможности подключения Crystal Reports к Delphi: 1. Использование функций Report Engine API из библиотеки CRPE32 DLL. В этом случае следует добавить в проект модуль CRPE32.PAS и сослаться на этот модуль в предложении uses. Ниже приведен пример соответствующего кода: procedure TForm1.Button1Click(Sender: TObject); VAR RepNam:PChar; begin if OpenDialog1.Execute then begin If PEOpenEngine then begin RepNam := StrAlloc(80); StrPCopy(RepNam, OpenDialog1.Filename); JN := PEOpenPrintJob(RepNam); if JN = 0 then ShowMessage('Ошибка открытия отчета'); StrDispose(RepNam); end else ShowMessage('Ошибка открытия отчета'); end; end; procedure TForm1.Button2Click(Sender: TObject); begin PEClosePrintJob(JN); PECloseEngine; Close; end;
procedure TForm1.Button3Click(Sender: TObject); begin PEOutputToWindow(jn,'Пример использования Crystal Reports Print Engine',30,30,600,400,0,0) ; if PEStartPrintJob(JN, True) = False then ShowMessage('Ошибка вывода отчета'); end; end.
Следует помнить, что строковые параметры, передаваемые в функции Print Engine API, представляют собой тип данных PChar, а не стандартные строки, используемые в Pascal, поэтому для передачи таких параметров, как, например, имя отчета, следует осуществить преобразование типов с помощью функции StrPCopy. Для успешной компиляции подобных приложений файл CRPE32.PAS должен находиться в том же каталоге, что и разрабатываемое приложение, либо в каталоге Delphi\Lib. 2.
Использование VCL-компонента и комплекта поставки ( для этого следует установить его в палитру компонентов Delphi). Естественно, этот компонент инкапсулирует те же самые функции Print Engine API. Существуют также аналогичные компоненты третьих фирм (например, компонент от SupraSoft Ltd., ).
3. Использование элемента управления Crystal Reports ActiveX. Этот элемент управления может быть установлен в палитру компонентов Delphi. Он обладает набором свойств и методов, более или менее сходным с соответствующим VCL-компонентом из комплекта поставки Crystal Reports Professional. 5. Использование Crystal Reports как сервера автоматизации. В справочной системе Crystal Reports имеется подробное описание иерархии вложенных объектов и их методов (и внушительный набор примеров для Visual Basic, аналоги которых несложно создать и на Pascal). Ниже приведен пример соответствующего кода: procedure TForm1.Button1Click(Sender: TObject); var r,rep: Variant; begin rep:=CreateOleObject('Crystal.CRPE.Application'); r:=rep.OpenReport('d:\Report2.rpt'); r.RecordSelectionFormula := '{items.ItemNo} = '+Edit1.Text; r.Preview; r:=Unassigned; rep:=Unassigned; end;
6. Можно также сделать отчет в виде исполняемого файла и вызвать его из приложения. Но в этом случае в отчет не удастся передать параметры.
QSA Designer
QSA Designer - это инструмент, который пользователи и разработчики используют для создания, редактирования, выполнения и отладки сценариев. QSA Designer включен в QSA-библиотеку и доступен всем приложениям. Кроме длинного названия QSA Designer включает средство создания GUI-интерфейса, аналогичное имеющемуся в Qt Designer, редактор кода Qt Script и интегрированный отладчик.

Интегрированная среда разработки использует те же самые подходы в создании GUI-интерфейса, что и Qt Designer. Пользователи могут приближенно размещать элементы интерфейса и выбором одного из типов компоновок в панели инструментов создавать масштабируемые диалоги. Также среда разработки позволяет легко связывать сигналы со слотами.
Если у пользователей не должно быть возможности создавать собственные диалоги, разработчики могут отключить возможности создания GUI в среде QSA Designer. В этом режиме пользователи могут создавать, редактировать, выполнять и отлаживать лишь не-GUI функции.
QSA Designer включает полностью интегрированный отладчик, который предлагает точки останова, пошаговое выполнение, отслеживание переменных и окно стека. Если в процессе отладки курсор мыши остановить над переменной, в окне всплывающей подсказки отобразится тип переменной и ее значение. Редактор кода имеет подсветку синтаксиса, авто-завершение, подсказку аргументов и сворачивание.
Работа с дисководами и папками
Объектная модель FSO может работать с дисководами и папками точно так же, как вы работаете с ними с помощью Windows Explorer в интерактивном режиме, т.е. вы можете копировать и перемещать файлы, получать информацию относительно дисководов и папок, и т.д.
Получение информации о дисководах
Объект Drive позволяет вам получать информацию о различных дисководах, присоединенных к системе или физически или через сеть. Его свойства позволяют Вам получить следующую информацию: полный размера дисковода в байтах (свойство TotalSize); количество доступного свободного места на дисководе в байтах (свойства AvailableSpace или FreeSpace); буквенное обозначение дисковода (свойство DriveLetter); тип дисковода: сменный, фиксированный, сетевой, CD-ROM или виртуальный (свойство DriveType); серийный номер дисковода (свойство SerialNumber); тип файловой системы, используемой на носителе: FAT, FAT32, NTFS и т.д. (свойство FileSystem); готов ли дисковод для использования (свойство IsReady); имя ресурсов общего доступа и метку диска (свойства ShareName и VolumeName); путь к устройству или его корневой папке (свойства Path и RootFolder).
Пример использования объекта Drive (Дисковод)
На пример ниже показывается как использовать объект Drive, чтобы получить полную информацию о дисководе. Не забудьте, что в следующем коде все обращения к фактическому объекту Drive осуществляются с помощью переменной drv, содержащей ссылку на объект, которая получена с помощью метода GetDrive:
Private Sub Command3_Click() Dim fso As New FileSystemObject, drv As Drive, s As String Set drv = fso.GetDrive(fso.GetDriveName("c:")) s = "Drive " & UCase("c:") & " - " s = s & drv.VolumeName & vbCrLf s = s & "Total Space: " & FormatNumber(drv.TotalSize/1024, 0) s = s & " Kb" & vbCrLf s = s & "Free Space: " & FormatNumber(drv.FreeSpace/1024, 0) s = s & " Kb" & vbCrLf MsgBox s End Sub
Работа с файлами
Вы можете работать с файлами в Visual Basic как используя новые объектно-ориентированные методы типа Copy, Delete, Move и OpenAsTextStream, так и с помощью старых функций - Open, Close, FileCopy, GetAttr и т.д. Обратите внимание, что вы можете перемещать, копировать или удалять файлы независимо от типа файла. Имеются две главных категории манипулирования файлами: создание, добавление или удаления данных или чтение файлов; перемещение, копирование и удаление файлов.
Создание файлов и добавления данных с помощью File System Objects
Есть три способа создать последовательный текстовый файл (иногда упоминаемый как "текстовый поток", text stream). Один путь состоит в том, чтобы использовать метод CreateTextFile. Например, создаем пустой текстовый файл: Dim fso As New FileSystemObject, fil As File Set fil = fso.CreateTextFile("c:\testfile.txt", True)
Обратите внимание, что текущая версия FSO еще не поддерживает создание произвольных (random) или двоичных (binary) файлов.
Другой путь состоит в том, чтобы использовать метод OpenTextFile объекта FileSystemObject с установкой флага ForWriting: Dim fso As New FileSystemObject, ts As New TextStream Set ts = fso.OpenTextFile("c:\test.txt", ForWriting)
Третий путь - вы можете использовать метод OpenAsTextStream с установкой флага ForWriting: Dim fso As New FileSystemObject, fil As File, ts As TextStream Set fso = CreateObject("Scripting.FileSystemObject") fso.CreateTextFile ("test1.txt") Set fil = fso.GetFile("test1.txt") Set ts = fil.OpenAsTextStream(ForWriting)
Добавление данных к файлу
Когда текстовый файл создан, вы можете добавлять в него данные. Для этого необходимо: открыть текстовый файл для записи данных; записать данные; закрыть файл.
Чтобы открыть файл вы можете использовать любой из двух методов: метод OpenAsTextStream объекта File или метод OpenTextFile объекта FileSystemObject.
Чтобы записать данные в открытый текстовый файл, используйте методы Write или WriteLine объекта TextStream. Единственное различие между Write и WriteLine - то, что WriteLine добавляет символы новой строки к концу строки. Если Вы хотите добавлять символы новой строки в текстовый файл без записи других символов, используйте метод WriteBlankLines.
Чтобы закрыть открытый файл, используйте метод Close объекта TextStream.
Sub Create_File() Dim fso, txtfile Set fso = CreateObject("Scripting.FileSystemObject") Set txtfile = fso.CreateTextFile("c:\testfile.txt", True) 'Запись линии txtfile.Write ("This is a test. ") 'Запись линии с символом newline txtfile.WriteLine("Testing 1, 2, 3.") 'Запись трех символов newline в файл txtfile.WriteBlankLines(3) txtfile.Close End Sub
Работа с папками
Этот список показывает общие задачи работы с папками и методы для их выполнения:
| Задача | Метод |
| Создать папку | FileSystemObject.CreateFolder |
| Удалить папку | Folder.Delete или FileSystemObject.DeleteFolder |
| Переместить папку | Folder.Move или FileSystemObject.MoveFolder |
| Копировать папку | Folder.Copy или FileSystemObject.CopyFolder |
| Возвратить имя папки | Folder.Name |
| Выяснить, существует ли папка на дисководе | FileSystemObject.FolderExists |
| Получить образец существующего объекта Folder | FileSystemObject.GetFolder |
| Выяснить имя папки, родителя папки | FileSystemObject.GetParentFolderName |
| Выяснить путь системных папок | FileSystemObject.GetSpecialFolder |
Пример ниже показывает использование объектов Folder и FileSystemObject для управления папками и получения информацию о них:
Private Sub Command10_Click() 'Получаем образец FileSystemObject Dim fso As New FileSystemObject, fldr As Folder, s As String ' Объект Get Drive Set fldr = fso.GetFolder("c:") ' Печатаем родительское имя папки Debug.Print "Parent folder name is: " & fldr ' Печатаем имя дисковода Debug.Print "Contained on drive " & fldr.Drive ' Печатаем имя корневой папки If fldr.IsRootFolder = True Then Debug.Print "This folder is a root folder." Else Debug.Print "This folder isn't a root folder." End If ' Создаем новую папку объектом FileSystemObject fso.CreateFolder ("c:\Bogus") Debug.Print "Created folder C:\Bogus" ' Печатаем основное имя папки Debug.Print "Basename = " & fso.GetBaseName("c:\bogus") ' Удаляем недавно созданную папку fso.DeleteFolder ("c:\Bogus") Debug.Print "Deleted folder C:\Bogus" End Sub
Распределенные инстанции
Инстанции Flora/C+ могут исполняться на разных процессорах, серверах или узлах кластерной платформы. Взаимодействие элементов дерева объектов одной инстанции с элементами другой инстанции осуществляется с помощью специальных сетевых средств (Flora Net), поддерживаемых объектной машиной. Предусмотрены два механизма взаимодействия объектов: порты ввода/вывода, используемые для поточной передачи данных между объектами разных инстанций и общее дерево объектов, являющееся частью дерева объектов нескольких инстанций.
Расширяемость системы
При использовании какой-либо прикладной системы служб вместе с MQSeries требуется через MQI разработать компонент доступа к очередям. Для многих распространенных программных средств уже существуют готовые модули. Для тех случаев, когда необходимы дополнения к базовой функциональности системы передачи сообщений, существуют документированные и открытые интерфейсы подключения внешних модулей, которые, например, позволяют опознавать системы, кодирования сообщений, компрессию данных и т.д.
MQSeries Link for SAP R/3. Этот модуль обеспечивает возможность интеграции R/3 c другими прикладными системами или удаленными системами R/3. MQSeries Link взаимодействует с компонентом ALE (Application Link Enabling) системы R/3, который отвечает за коммуникацию между распределенными подсистемами R/3. Прикладные данные, циркулирующие в форматах внутренних промежуточных документов IDoc системы R/3, преобразуются в сообщения MQSeries и посылаются другой системе. Посылка/прием сообщений MQSeries происходит под контролем транзакций R/3.
Сопряжение MQSeries с LotusNotes. Для организации взаимодействия MQSeries с Lotus Notes существует целый ряд программных компонентов: MQ Enterprise Integrator, MQSeries LSX, MQSeries Link, MQSeries Extra Link. С их помощью пользователи могут посылать данные и документы Lotus Notes в другие системы через MQSeries и получать в ответ сообщения для обновления документов Lotus Notes. Расширение стандартного языка программирования Lotus Script - MQSeries LSX, предоставляет набор из нескольких классов, реализующих интерфейс MQI для клиентских и серверных приложений Lotus. Использование других компонентов, таких как MQEnterprise Integrator, представляющих собой настраиваемые приложения Lotus Notes, не требует непосредственного программирования. При настройке обычно используются специальные базы данных Notes, содержащие сведения об очередях MQSeries, описания структуры посылаемого и возвращаемого сообщения, названия обновляемых документов и информацию о конвертации пересылаемых данных.
Доступ в Internet. MQSeries Internet Gateway представляет собой шлюз между Web сервером и системой MQSeries, преобразующий запросы пользователей браузеров в сообщения MQSeries с последующей отправкой сообщений приложениям и преобразованием полученных обратно сообщений в формат HTML.
Кроме того, с Web-сервера может быть загружен в виде апплета MQSeries Java клиент, который будет принимать и посылать сообщения с гарантированной доставкой через менеджеры MQSeries. MQSeries предполагает использование и других технологий из области промежуточного ПО. Например, сервисов DCE (Distributed Computer Environment), позволяющих приложению прозрачно обращаться к очереди сообщений, относящейся к той же ячейке DCE без определения этой очереди как удаленной, а также выполнять аутентификацию пользователей и контролировать доступ к очередям при помощи служб безопасности DCE.

"Разбор полетов"
Грянул выстрел в тишине,
Взвил воронью стаю,
На войне как на войне -
Иногда стреляют.
А. Розенбаум
Итак, используя минимум понятий и средств, мы за два шага (первый - в работе [1], второй - здесь) превратили весьма ограниченный по своим возможностям исходный пример, предложенный программистами Microsoft, в более интересный, решающий к тому же весьма актуальную и не такую уж простую проблему синхронизации параллельных процессов.
Кроме того, задача Майхилла по духу ближе разработчикам игровых программ, которые часто используют модель КА для описания поведения персонажей[4]. Им в этот раз особое внимание и поклон!
Итак, решая задачу Майхилла, мы: увидели, насколько эффективным и простым может быть решение нетривиальных проблем с использованием формальных моделей (попробуйте решить рассмотренную задачу обычными "фирменными" средствами!); познакомились с тем, как можно изменить алгоритм работы объекта, модифицировав таблицу переходов; узнали, как автоматически удалять автоматные параллельные процессы (раньше мы умели только порождать их); научились создавать информационные связи между автоматными объектами и синхронизировать поведение объектов с помощью их внутренних состояний; используя параллелизм среды и динамическое порождение объектов, смоделировали более сложную ситуацию, не предусмотренную исходной задачей; создали "скелет" задачи о системе из множества объектов с информационными связями между ними; он применяется как в рассмотренных ранее задачах о триггере и о мячиках, так и в нынешней задаче о стрельбе.
Пуля может быть "дурой", а может обладать "интеллектом" ПТУРСa. Так, можно резко повысить эффективность поражения целей стрелками, научив их стрелять еще и "веером". Поведение стрелков можно усложнить, заставив их передвигаться, взаимодействовать, стрелять одиночными и очередями. При разборе примера обратите внимание на то, как реализуется формирование паузы между пулями с помощью "автоматной задержки" CFDelay. Задержка - еще один вариант использования автоматных подпрограмм.
В примере стрельба очередью организуется с помощью дополнительных действий стрелка y4, y5 и предиката x4, а свойство класса стрелка nLengthQueue определяет длину очереди из пуль. Необходимые изменения внесены и в таблицы переходов пули и стрелка.
Возможны и другие варианты развития примера - были бы время и желание (и заказчики, конечно!). Со временем бывает туго, но одна из целей FSA-библиотеки - помочь его сберечь. Удачной вам охоты (с автоматами) в "программных джунглях" и до новых встреч!
Разработка спецификации архитектуры системы – переход от концептуальной модели к программной модели
После того как руководитель проекта получил функционально-ориентированную и объектно-ориентированную картину системы, ему необходимо «объединить» их воедино и получить спецификацию системы, которую можно выдавать программистам на реализацию в программный код.
Необходимо взять часть прецедентов использования и построить для каждого из них диаграмму взаимодействия, например, диаграмму кооперации (collaboration diagram). Пример такой диаграммы изображен на рис.3.

Рис. 3.
Во время построения диаграмм взаимодействия будут выделены публичные (public) методы классов, а также появятся классы чисто синтетической природы, которые не имеют аналогов в реальном мире. Этот этап, на мой взгляд, самый сложный и в нем можно допустить ошибки, которые будут тянуться на протяжении всего проекта. Вот по этой причине руководитель среднего программного проекта должен уметь не только программировать, но и иметь навыки работы программным архитектором (Software Architect).
Существуют так называемые шаблоны проектирования (design patterns), которые следует применять на этом этапе. Встает проблема распределения обязанностей между объектами и разработке взаимодействия объектов. Для успешного конструирования следует систематизировать и тщательно проанализировать принципы разработки. Такой подход к пониманию и использованию этих принципов основывается на применении шаблонов распределения обязанностей GRASP. Другой набор шаблонов – шаблоны GoF, которые не строго ориентированы на распределение обязанностей, а ориентированы на повторное использование дизайна и являются чисто синтетическими конструкциями, не имеющими никакого отношения к объектам реального мира. Всего выделяются три группы шаблонов. Порождающие шаблоны проектирования абстрагируют процесс создания объектов. В структурных шаблонах рассматривается вопрос о том, как из классов и объектов образуются более крупные структуры. Шаблоны поведения связаны с алгоритмами и распределением обязанностей между объектами. Результатом дизайна будет несколько диаграмм классов.
Пример такой диаграммы показан на рис. 4.

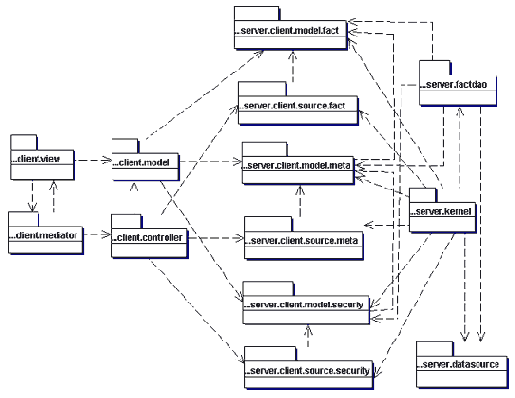
Разрядная архитектура
Win64-код объединяет в себе основные возможности 32-разрядного кода, а также включает изменения, связанные с повышением разрядности. В распоряжении программиста оказываются: 64-разрядные указатели; 64-разрядные типы данных; 32-разрядные типы данных; интерфейс Win64 API.
Обратите внимание, что 32-разрядные типы данных не исчезли при повышении разрядности платформы (как было с 16-разрядными типами данных при переходе к Win32). Это связано с тем, что даже в 64-разрядных приложениях в большинстве случаев переменные не требуют объема памяти в 8 байт, поэтому использование 64-разрядных типов в таких случаях оказалось бы крайне неэффективным. Операционной системе пришлось бы дописывать нули в старшие разряды, чтобы увеличить размер данных до 8 байт (такие данные к тому же очень неудобно считывать). Это привело бы к снижению производительности.
Иная участь постигла 32-разрядные указатели: они полностью исчезли. Дело в том, что использование 32-разрядных указателей накладывает ограничение на объем адресуемой памяти. Например, одним из главных преимуществ плоской модели памяти (она является основной для программирования 32-разрядных приложений для платформы NT), использующей 32-разрядные указатели, является возможность создания сегментов объемом до 4 Гбайт. Новые 64-разрядные указатели обеспечивают возможность адресации до 16 Тбайт памяти (1 Тбайт = 1012 Мбайт). Современными бизнес-приложениями этот объем вполне востребован.
Функции в Win64 API претерпели незначительные изменения. Только названия некоторых из них были изменены так, чтобы отразить принадлежность к 64-разрядной платформе. В большинстве случаев изменениям подверглись лишь типы параметров, являющихся аргументами вызова функций. Все остальные преимущества (возможность отказаться от использования файлов подкачки и т. д.) связаны либо с увеличившимся объемом адресации, либо с новыми типами данных.
Разрядное приложение в 64-разрядной среде
Если бы 32-разрядные приложения работали в 64-разрядной среде так же эффективно, как в , не было бы никакого смысла не только писать эту статью, но и создавать 64-разрядный компилятор. Действительно, производительность 32-разрядных приложений при работе на 64-разрядной платформе существенно снижается. Это связано с тем, что для запуска 32-разрядного приложения операционной системе приходится выполнять ряд подготовительных действий: увеличивать все 32-разрядные указатели до размера в 8 байт, преобразовывать вызовы API-функций, заменять типы 32-разрядных данных на 64-разрядные.
Здесь следует остановиться и подробнее рассмотреть вопрос о преобразовании данных. Win64 допускает использование и 32-, и 64-разрядных данных. Поэтому когда операционная система встречает 32-разрядные данные в 32-разрядном приложении, она должна ответить на вопрос: Делается это для того, чтобы оптимизировать работу приложения. Если операционная система встретит 32-разрядные данные в 64-разрядном приложении, то не обратит на них внимания, так как платформа Win64 допускает использование 32-разрядных типов данных. Преобразование 32-разрядных данных в 64-разрядные осуществляется точно так же, как и преобразование 32-разрядных указателей, - дописыванием нулей в старшие разряды. Очевидно, что на выполнение всех этих операций тратится масса системных ресурсов, и, как результат, производительность снижается. Это особенно заметно при работе 32-разрядных драйверов на 64-разрядной платформе. В связи с тем, что драйверы являются связующим звеном между оборудованием и операционной системой, именно они используются наиболее интенсивно.
Развертывание информационной системы
Если Вы указали корректные настройки в Архитекторе приложений (каталог сервера приложений, каталог Java SDK и т.д.), то Rapid Developer позволяет запустить сервер приложений, выполнить развертывание разрабатываемой информационной системы в необходимой папке сервера приложений и осуществить ее запуск.
Развернуть на стороне сервера приложений можно как всю систему целиком, так и любую ее часть (например, отдельную страницу).
Запуск сервера приложений осуществляется с помощью пункта главного меню "Tools/Start Server/J2EE Application Server".
При выделении Web-страницы в Архитекторе сайта или для открытой страницы в Архитекторе Web-страниц становится доступным пункт меню "Tools/Web Page Preview", активизация которого позволяет запустить разрабатываемое приложение в виде Web-броузера, в котором открыта данная страница.
Развитая мультизадачность
Любой элемент или группа элементов объектного дерева может быть отдельной задачей.
Возникающие коллизии решаются автоматически с помощью встроенных средств объектной машины. С целью эффективной организации асинхронной обработки событий в задачах разработан специальный класс объектов, называемый рефлексами.
Создание мультизадачных приложений в технологии Flora/C+ является правилом, а не исключением, как это обычно принято. Даже в приложениях среднего размера может порождаться несколько десятков и даже сотен параллельно исполняемых задач.
Развитые средства визуализации
Библиотеки Flora/C+ содержат широкий набор классов графических объектов. Свойства всех графических объектов, в том числе. координаты, цвет, форма и т.д. доступны для их динамического изменения в процессе исполнения другими объектами приложения Все изменения моментально отражаются на системном экране. На основе этих простых и ясных для разработчика возможностей и средств могут быть реализованы сложные анимационные эффекты, значительно усиливающие графические возможности прикладных интерфейсов.
Реализация сценария регистрации
Сценарий мониторинга для выполнения регистрации необходимо установить на локальном жестком диске каждого компьютера по одному из многих путей, где Windows ищет программы, которые следует инициализировать при регистрации пользователя. Сценарий нужно настроить так, чтобы он выполнялся в контексте соответствующего пользователя; в этом случае соединения и другие функции сценария регистрации будут выполняться с применением учетных данных пользователя. Не будем забывать, что пользователи порой склонны экспериментировать с объектами своих папок Startup, поэтому инициализировать сценарий следует с использованием раздела реестра HKEY_CURRENT_USER\Software\Microsoft\Windows\ CurrentVersion\Run.
Поскольку этот "связывающий" сценарий должен быть установлен на каждом компьютере, следует заранее продумать, как вы будете при необходимости обновлять его. Приложив некоторые старания и проявив смекалку, вы сможете модифицировать сценарий так, чтобы его обновление осуществлялось автоматически.
Средства мониторинга событий службы WMI позволят решить проблему, с которой сталкиваются многие администраторы Windows. Надеюсь, что применение средств WMI для запуска сценария регистрации дает некоторое представление о новых возможностях применения сценариев, которые открывает перед нами эта служба.
Дарвин Саной  - старший консультант в DesktopEngineer.com. Регулярно выступает на конференции Microsoft Management Summit, читает курс по Windows Installer. С ним можно связаться по адресу: .
Редактирование файлов
После того, как CVS создал рабочее дерево каталогов, вы можете обычным образом редактировать, компилировать и проверять находящиеся в нем файлы -- это просто файлы.
Например, предположим, что мы хотим скомпилировать проект, который мы только что извлекли: $ make gcc -g -Wall -lnsl -lsocket httpc.c -o httpc httpc.c: In function `tcp_connection': httpc.c:48: warning: passing arg 2 of `connect' from incompatible pointer type $
Кажется, `httpc.c' еще не был перенесен на эту операционную систему. Нам нужно сделать приведение типов для одного из аргументов функции connect. Чтобы сделать это, надо изменить строку 48, заменив if (connect (sock, &name, sizeof (name)) >= 0)
на if (connect (sock, (struct sockaddr *) &name, sizeof (name)) >= 0) $ make gcc -g -Wall -lnsl -lsocket httpc.c -o httpc $ httpc GET http://www.cyclic.com
...здесь находится текст HTML с домашней страницы Cyclic Software ...
$
Для того, чтобы писать полноценные
Для того, чтобы писать полноценные приложения под Win32 требуется не так много: собственно компилятор и компоновщик (я использую связку TASM32 и TLINK32 из пакета TASM 5.0). Перед использованием рекомендую "наложить" patch, на данный пакет. Patch можно взять на site или на нашем ftp сервере ftp.uralmet.ru. редактор и компилятор ресурсов (я использую Developer Studio и brcc32.exe); выполнить перетрансляцию header файлов с описаниями процедур, структур и констант API Win32 из нотации принятой в языке Си, в нотацию выбранного режима ассемблера: Ideal или MASM. В результате у Вас появится возможность писать лёгкие и изящные приложения под Win32, с помощью которых Вы сможете создавать и визуальные формы, и работать с базами данных, и обслуживать коммуникации, и работать multimedia инструментами. Как и при написании программ под DOS, у Вас сохраняется возможность наиболее полного использования ресурсов процессора, но при этом сложность написания приложений значительно снижается за счёт более мощного сервиса операционной системы, использования более удобной системы адресации и весьма простого оформления программ.
Количество и разнообразие деловых приложений, которые скоро появятся, колоссально. Jaguar CTS и другие, находящиеся на стадии становления, технологии Сети устраняют преграды по развертыванию серьезных деловых приложений в Интернет, которые стояли перед разработчиками предшествующие пару лет. Поскольку организации и заказчики начинают понимать удобство, индивидуальный сервис и экономию средств от применения WebOLTP, Интернет-приложения будут иметь логарифмический рост количества приложений, предлагающих крупномасштабную обработку транзакций.
Сценарий мониторинга выполнения регистрации (Logon Monitor Script)
В первых двух строках сценария, представленного в , определяются две переменные, речь о которых впереди. В метке A Листинга 1 функция GetObject устанавливает соединение с WMI и создает запрос об извещении о событии. В строке SELECT указывается, что сценарий должен получать имя (TargetInstance.Name) любого нового или измененного экземпляра (FROM_InstancdOperationEvent) класса WMI, представляющего сетевые соединения (TargetInstance ISA 'Win32_NetworkAdapterConfiguration'). Стоит отметить, что объект Win_32_NetworkAdapterConfiguration включает в себя все сетевые соединения вне зависимости от того, используются ли для их осуществления физические сетевые адаптеры. При установлении соединений RAS, VPN или других типов соединений API RAS или VPN создает "виртуальный адаптер", который затем появляется в данном классе WMI. При обнаружении новых соединений RAS или VPN, а также при подключении к сети новой сетевой интерфейсной платы после регистрации пользователя объект _InstanceOperationEvent извещает сценарий об этих событиях. (Вообще-то объект _InstanceOperationEvent извещает сценарий и об удалении соединения, однако в данном сценарии такие это не предусматривается.)
Служба WMI извещает сценарий обо всех событиях, соответствующих критериям запроса. Раздел запроса WITHIN 4 означает время в секундах, выделяемое внутреннему механизму WMI для проведения опроса класса о наличии событий. Как я уже говорил, механизм этого внутреннего опроса весьма эффективен. Желающие проверить, не оборачивается ли данный запрос о событиях дополнительной нагрузкой на процессор, могут установить наблюдение за службой WMI с помощью средства Performance Monitor. Это средство покажет, что выполнение сценария не приводит к непроизводительной затрате ресурсов процессора. Большинство версий Windows (включая Windows 2000) вызывают службу WMI [через файл] winmgmt.exe. В среде Windows XP служба WMI является экземпляром svchost.exe. Для того чтобы точно определить непроизводительные расходы процессора, необходимо сравнить значения счетчиков производительности процессора - в расчете на процесс - до запуска сценария и во время его выполнения.
Цикл Do.
Цикл Do рассматриваемого сценария не является бесконечным циклом опроса; он обеспечивает постоянный мониторинг событий соединения.
Без этого цикла сценарий выполнялся бы только один раз. Сценарий должен находиться в этом цикле для того, чтобы обрабатывать ситуации, в которых пользователи, подключенные к сети с помощью соединений VPN, RAS или через Dynamic NIC, воздерживаются от выключения своих портативных компьютеров (переводя их в режим ожидания или "спячки").
Строка в метке B позволяет обходиться без опроса по событиям конфигурации (который проводится традиционными сценариями мониторинга). Рассматриваемый сценарий в данной точке исполнения ждет от WMI извещения о наступлении события, соответствующего указанным критериям. Когда служба WMI извещает сценарий о наступлении такого события, выполнение продолжается со следующей строки.
В следующей строке указывается, что объект соединения должен обязательно возвращать строку, содержащую свойство Ipaddress. При таком подходе автоматически отфильтровывается несколько типов нежелательных событий - прежде всего, события удаления соединения, которые не возвращают массива строк для переменной IP-адреса.
Кроме того, некоторые типы соединений (например, соединения VPN) до получения действительного IP-адреса предусматривают многочисленные модификации экземпляра Win32_NetworkAdapterConfiguration. Проверка VarType гарантирует, что сценарий мониторинга будет игнорировать подобные промежуточные события.
Функция SubnetMatch.
Базовый метод, используемый сценарием Logon Monitor для идентификации целевой сети, важен в двух отношениях. Он позволяет, во-первых, сокращать число "ложных срабатываний" при взаимодействии с другими сетями, а во-вторых - блокировать попытки главного сценария запускать сценарий регистрации в случаях, когда класс Win32_NetworkAdapterConfiguration выявляет изменения в других типах соединений. Некоторые типы протоколов-упаковщиков, как, впрочем, и инфракрасные порты, тоже создают и модифицируют этот список экземпляров данного класса. Процедура согласования подсетей позволяет отфильтровывать указанные ситуации и предотвращать запуск сценариев регистрации в неподходящих случаях.
Функция SubnetMatch обеспечивает успешный поиск подсети, отвечающей заданным критериям.
Построчное разъяснение механизма действия этой функции выходит за рамки данной статьи, но все же читателю нужно знать, какие услуги данная функция предоставляет. Итак, функция SubnetMatch использует IP-адрес соответствующего компьютера и ищет подобные адреса в предоставленном списке подсетей. Функция возвращает булево значение ("истина" или "ложь") и помещает список совпадений в массив.
Программу SubnetMatch можно применять в сетях, разделенных на подсети без использования классов, поэтому она дает точные результаты в сетях при использовании самых разных способов разделения сетей на подсети. Функции передается список подсетей, так что можно включать в него отдельные подсети, выделенные по логическим критериям, например, Building A (строение А), London Campus (лондонский кампус) или Finance Division (финансовый отдел).
Для получения точных совпадений по сегменту смежных подсетей можно использовать адреса надсетей (supernet addresses). Чаще всего надсети применяются для обозначения любого соединения со всей сетью компании. Если в компании используется единый адрес класса B, можно задействовать этот адрес вместо длинного списка подсетей. Применение надсетей позволяет упростить сценарий и повысить быстродействие функции поиска совпадений в сложных сетях. Когда вы будете использовать надсети, вероятность того, что сценарий найдет совпадения в сетях за пределами целевой сети, будет выше.
Для того чтобы идентифицировать сети с исключительно высокой степенью точности, сценарий можно модифицировать так, чтобы он извлекал из анализируемого события объект TargetInstance и сопоставлял значения других атрибутов TCP/IP и соединений. Суффикс DNS, WINS Servers и DNS Servers могут служить примерами уникальных идентифицирующих данных, которые позволяют удостовериться в том, что соединение установлено со всей сетью. Позднее мы рассмотрим вопрос о мягких аварийных переключениях (graceful failover), а в этом разделе будет показано, как сценарий обрабатывает ситуации с ложными совпадениями.
Код в метке C вызывает функцию SubnetMatch.
Функция принимает четыре параметра. Первый из них - это предоставляемый список подсетей (aSubnetList). Данный массив представляет собой список IP-адресов и пар масок подсетей, разделенных косой чертой (/). Поскольку список обрабатывается последовательно, на первых позициях следует размещать подсети, соответствующие адресам наибольшего числа компьютеров (возможен такой порядок: надсети, затем подсети с наибольшим числом мобильных клиентов, затем другие подсети).
Второй параметр - это IP-адрес соединения, возвращенный сценарию службой WMI. Сценарий рассматривает данный адрес как часть объекта ConnectEvent с именем Connect-Event.TargetInstance.Ipaddress(0). Для извлечения многих других атрибутов соединения можно использовать другие имена свойств класса Win32_NetworkAdapterConfiguration.
Третий параметр - bAllMatches. Если он получает значение "истина", функция SubnetMatch находит все совпадения. Если же параметру задано значение "ложь", SubnetMatch ограничивается обнаружением первого совпадения. Если сценарий должен проверить множество подсетей, более высокое быстродействие достигается при использовании значения "ложь".
Четвертый параметр представляет собой имя массива, в который функция SubnetMatch поместит список совпадений. Этот массив будет содержать более одного значения лишь в том случае, если параметру bAllMatches будет присвоено значение "истина". Получение всех совпадений может оказаться полезным при отладке обширных списков подсетей. Передавать сценарию информацию о том, какие подсети соответствуют заданным критериям, нет необходимости (данная видовая программа поиска подсетей предназначена для обработки большого количества объектов), так что списки сценарию не возвращаются.
Функция SubnetMask выполняет некоторые расчеты, определяет, какие подсети из списка aSubnetList соответствуют IP-адресу того или иного компьютера, и возвращает логическое значение ("истина" или "ложь"), которое показывает, найдено ли совпадение.Соответствующая строка в метке D предназначена для того, чтобы проверить, найдена ли функцией SubnetMatch соответствующая заданным критериям подсеть. Выполнение сценария продолжается лишь после завершения такой проверки.
Сегментация текста
Разбиение текста на сегменты является важным подготовительным этапом для полной или частичной автоматизации перевода. Сегменты должны по возможности содержать фрагменты текста, грамматически независимые друг от друга. Иными словами, должна быть обеспечена возможность корректного перевода каждого сегмента независимо от других. Обычно разбиение на сегменты выполняется по знакам пунктуации.
Семейство MQSeries
Предшественники средств МОМ появились при решении задач обмена данными между программами, когда разработчики писали собственные локальные или сетевые модули экспорта-импорта с использованием различных промежуточных хранителей: файлов, буферов памяти и т.д. Данное ПО долгое время существовало в виде вспомогательных и частных средств, однако в связи с выходом на первый план задач интеграции готовых прикладных систем между собой системы МОМ получили мощный стимул к развитию и стандартизации.
История MQSeries как единого семейства программных продуктов начинается с 1992 года, когда компания IBM опубликовала спецификации для программного интерфейса Message Queue Interface (MQI). В том же году было заключено соглашение между IBM и компанией System Strategies (SSI), которая тогда разрабатывала собственные продукты для передачи сообщений ezBRIDGE Transact, адаптированные для использования MQI.
Затем появилось несколько принципиально новых версий, существенно расширился круг платформ и функциональных возможностей MQSeries. Сегодня менеджеры очередей MQSeries работают на OS/390, MVS, VSE/ESA, OS/400, OS/2, Tandem Guardian и Himalaya, OpenVMS VAX, Digital Unix, AIX, HP-UX, SunOS, Sun Solaris, SCO UNIX, UnixWare, AT&T GIS UNIX, DC/OSx, Windows NT/95/3.1. Для еще большего числа платформ, в том числе для DOS, Java, MacOS, Linux, существуют MQSeries клиенты. Взаимодействие менеджеров очередей MQSeries даже разных версий происходит прозрачно для внешних программ, что обеспечивает им единый интерфейс MQI и функционирование единой транспортной системы MQSeries.
Можно указать ряд направлений развития MQSeries и всей архитектуры средств МОМ: появляются новые прикладные и административные интерфейсы, упрощающие процесс создания новых систем; поддерживаются более сложные модели обработки сообщений, такие как публикация-подписка или обработка с анализом контекста сообщений; развивается интеграция между MQSeries и реляционными базами данных; появляются решения для поддержки совместной работы нескольких менеджеров очередей, соединенных в кластеры.
Сервер транзакций Powersoft Jaguar CTS
Powersoft Jaguar CTS - новый сервер транзакций, разработанный специально для WebOLTP (см. Рисунок 6). Компания Sybase, Inc. осуществила первую поставку Jaguar CTS SDK в феврале 1997 и планировала начать распространение Web SDK начиная со второго квартала 1997. Основные возможности Jaguar CTS включают в себя:
Масштабируемый, независимый от платформы механизм выполнения. Быстрая связь между всеми уровнями. Компонентная разработка с поддержкой всех ведущих моделей компонентов, включая: ActiveX, JavaBeans, и объекты CORBA. Полная поддержка защиты в Internet, включая SLL шифрование и аторизацию, а также списки управления доступом к уровню приложений. Гибкое управление транзакциями с поддержкой как обычной синхронной, так и асинхронной диалоговой обработки запросов.
Рисунок 6. Powersoft Jaguar CTS - новый сервер транзакций, разработанный специально для WebOLTP.
Исполняемый модуль Jaguar CTS
Исполняемый модуль Jaguar CTS разработан таким образом, чтобы обеспечить надежную, масштабируемую производительность для большого количества пользователей WebOLTP. Это означает:
Наличие масштабируемого, многопоточного ядра, поддерживающего работу в многопроцессорной системе. Расширенное управление сеансами и соединениями. Система администрирования и текущего контроля типа броузера.Одним из ключевых моментов в достижении Jaguar CTS высокой производительности является устойчивое, многопоточное ядро, работающее в многопроцессорной системе. При проектировании и разработке ядра Jaguar CTS компания Sybase использовала знания и технологии, накопленные за предшествующие шесть лет, полученные из опыта тысяч инсталляций предыдущих поколений серверных программ.
Это наследие позволяет ядру Jaguar CTS продемонстрировать следующие главные особенности:
Эффективный многопоточный режим, который использует собственные потоки операционной системы там, где это возможно. Встроенную поддержку потоков на платформах без собственных реализаций этого механизма. Специфические для компонентной реализации потоковые режимы, включая одиночные, выделенные и свободные потоки. Превосходная многопроцессорная масштабируемость. Расширенные параметры настройки для оптимизации эффективности в зависимости от используемых платформ и рабочих нагрузок.В дополнение к обеспечению эффективности ядро Jaguar CTS выполняет еще одну важную функцию: оно скрывает от разработчиков приложений сложности потоковой обработки, блокировок и управления памятью.
Почему это так важно? Представьте себе, что кто-то из крупных разработчиков, столкнувшись с задачей перехода к WebOLTP, будет учиться писать многопользовательские сервер-приложения. Сегодняшние разработчики приложений клиент/сервер, как правило, имеют опыт написания однопользовательских (для клиентской машины) приложений. Однако, находящаяся на стадии становления многоуровневая архитектура предполагает размещение большей части бизнес-логики на промежуточном уровне, где к ней обращаются и используют множество пользователей.
Многие системы, включая ORB и Web-серверы приложений, предоставляют разработчикам самим разбираться с потоками, блокировками и проблемами управления памятью. Чтобы еще хуже, эти проблемы должны решаться по-разному для каждой OS платформы.
Ядро Jaguar CTS значительно уменьшает эти проблемы, давая разработчикам доступ к легким в использовании, независимым от платформы средствам обеспечения многопоточной обработки, блокировок и управления памятью. Вместе взятые, эти средства улучшают производительность разработки, ускоряют отладку и увеличивают надежность при обеспечении общей производительности системы.
Управление сеансами и соединениями
По сравнению с традиционными системами клиент/сервер или универсальными СУБД, WebOLTP приложения - особенно Internet или extranet приложения - будут обслуживать намного большие группы пользователей. Это выдвигает перед разработчиком ряд проблем. Но при наличии эффективного управления сеансами и соединениями разработчики могут действительно управлять этими большими группами пользователей. “Управление сеансами” означает управление связями между броузером и сервером транзакций; “управление соединениями” означает управление связями между сервером транзакций и СУБД. Работая вместе, диспетчеры сеансов и соединений Jaguar CTS преобразуют большое количество сеансов броузера в намного меньшее число соединений с СУБД, улучшая таким образом общую масштабируемость системы при обеспечении более устойчивого времени отклика при переменных рабочих нагрузках. Диспетчер сеансов Jaguar CTS Session Manager, очевидно, управляет связями броузер-Jaguar CTS.
В отличие от большинства систем, сеансы Jaguar CTS не зависят от коммуникационного протокола. Это позволяет, например, начинать сеанс, используя общий протокол Сети , а затем подключать быстродействующий протокол поточной обработки данных, называемы по имени TDS (Tabular Data Stream). Управление этим взаимодействием внутри одного сеанса дает возможность серверу поддерживать информацию о “состоянии” и правах пользователя.
Диспетчер соединений Jaguar CTS Connection Manager, очевидно, управляет связями между Jaguar CTS и СУБД. Одной из главных особенностей Connection Manager является “объединение соединений” (connection pooling). Используя connection pooling, администратор Jaguar CTS может сформировать пул соединений с одной или большим количеством СУБД. Пользователи Jaguar CTS затем могут задействовать эти соединения в разделенном режиме. Connection pooling уменьшает общую нагрузку на стороне СУБД, управляя количеством одновременных соединений и уменьшая издержки соединения в расчете на одного пользователя. Эти возможности улучшают масштабируемость и уменьшают время ответа конечному пользователю. В дополнение к возможности создавать пул соединений, Connection Manager интегрируется с диспетчером транзакций Jaguar CTS Transaction Manager (см. раздел Управление транзакциями) и автоматически соотносит сеансы Jaguar CTS и транзакции системы управления базами данных.
Система администрирование и текущего контроля
Jaguar CTS поставляется с собственными простыми в использовании средствами системного администрирования и мониторинга. Написанный полностью на языке Java, Jaguar CTS Manager может быть запущен или в броузере, или как автономное Java-приложение на любой платформе, которая поддерживает Java. Jaguar CTS Manager позволяет администраторам:
Запускать / закрывать Jaguar CTS сервер.
Конфигурируйте основные параметры эффективности Jaguar CTS, типа памяти, количества потоков, сеансов и соединений.
Отслеживать производительность сервера и выполнение сервлет.
Поскольку зачастую границы между разработкой, тестированием, развертыванием и текущим администрированием размыты, система упрвления Jaguar CTS интегрирован с Jaguarом CTS Package Manager, описанный ниже.
Например, разработчики могут динамически развертывать новый компонент на Jaguar CTS и сразу же контролировать изменения производительности. Это позволяет администраторам использовать одно средство для управления приложениями на протяжении их полного жизненного цикла.
Соединяемость Jaguar CTS
В многоуровневой среде быстродействие соединения определяется в большей степени временем ответа конечному пользователю, чем любым другим фактором. Jaguar CTS предоставляет быстродействующее соединение с броузерами и back-end хранилищами данных при обеспечении оптимизированной соединяемости. Основные возможности соединяемости включают:
Обобщенную мультипротокольную поддержку броузеров и других клиентов Сети. Поддерживаемые протоколы включают HTTP, TDS (для быстродействующей обработки потоков данных) и протокол CORBA IIOP.
Соединяемость со всеми основными СУБД, включая Sybase SQL Server и SQL Anywhere, Oracle7.x и MS SQL Server через стандарты ODBC, JDBC и Sybase Open Client .
Соединяемость с mainframe и 20 другими источниками данных через семество продуктов доступа к данным EnterpriseConnect компании Sybase.
Быстродействующая соединяемость из Java как для апплетов, так и сервлетов.
Высокоскоростной обмен результирующими выборками между всеми уровнями.
Эффективное HTTP-туннелирование там, где необходимо обеспечить совместимость с .
Поддержка мультипротокольного режима работы
Многочисленные протоколы и стандарты протоколов - одна из самых горячих тем относительно Internet. Одни поставщики предлагают использовать расширенный протокол HTTP, в то время как другие рекомендуют работать с IIOP или DCOM. Jaguar CTS избавляет разработчиков от этих сложностей и неопределенностей, предоставляя обобщенную мультипротокольную поддержку между клиентами Сети и Jaguar CTS. Сервер Jaguar CTS может “говорить” на многих протоколах одновременно и даже объединять различные протоколы внутри одного сеанса. Это позволяет Jaguar CTS как поддерживать стандартные протоколы, так и обрабатывать потоки результирующих выборок, испльзуюз быстродействующий протокол TDS.
Также легко могут быть добавлены новые протоколы, чтобы удовлетворить требования пользователей или выполнять новые стандарты. Во всяком случае, Jaguar CTS делает прозрачность протоколов одной из основных парадигм для разработчиков приложений.
Соединяемость с СУБД
Jaguar CTS обеспечивает соединяемость почти со всеми back-end источниками данных. Основные СУБД включают Sybase SQL Server, SQL Anywhere, Oracle7, Microsoft SQL Server и Informix Online; соединяемость с этими источниками обеспечивается за счет стандартных интерфейсов ODBC и JDBC. Соединяемость с более чем двадцатью mainframe и другими источниками данных - включая DB2 IBM, IMS и VSAM - обеспечивается через EnterpriseConnect. Соединениями и транзакциями в базах данных управляют диспетчеры транзакций и соединений Jaguar CTS. Соединяемость с Java через jConnect
Благодаря важному значению Java в многих WebOLTP инсталляциях, в Jaguar CTS уделено особое внимание скорости соединения между Java апплетами, Java сервлетами и back-end СУБД. JDBC предлагает стандартный метод для Java-приложений, чтобы связываться с хранилищами данных. К сожалению, до настоящего времени большинство поставщиков не имеет своих Java-драйверов JDBC. Эти не-Java драйверы предусматривают установку и конфигурацию, сводящие на нет одно из основных преимуществ решений на основе Java. Кроме того, не-Java драйверы часто плохо работают, потому что они требуют по крайней мере одного дополнительного прохода процесса и часто дополнительные проходы сети, а также преобразования протоколов. Напротив, Jaguar CTS использует новый JDBC драйвер, известный как jConnect для JDBC. Написанный полностью на Java, jConnect быстр, имеет маленький размер (менее 200КБ кода), поддерживает связи как между апплетами и сервлетами, так и между сервлетами и СУБД.
Компонентная разработка Jaguar CTS
Из-за короткого жизненного цикла большинства WebOLTP-приложений, быстрая разработка и развертывание приложений обязательны для любого сервера транзакций. С самого начала Jaguar CTS создавался с целью облегчить труд разработчиков.
В этом плане Jaguar CTS имеет такие возможности как:
Поддержка мультикомпонентных моделей.
Интеграция RAD инструментальных средств.
Уникальный Package Manager для сборки связанных компонентов.
Встроенная обработка результирующей выборки.
Интеграция компонентов третьих фирм.
Поддержка мультикомпонентных моделей
Jaguar CTS изначально был разработан для поддержки обобщенных, мультикомпонентных моделей. Это позволяет с одного сервера Jaguar CTS одновременно выполнять сервлеты, сформированные в соответствии с любой популярной компонентной или объектной моделью, включая:
ActiveX
Java и JavaBeans
/ (собственные объекты)
CORBA (IDL)
Те же самые компонентные модели поддерживаются и для клиентских приложений (апплет). Jaguar CTS решает все проблемы удаленного вызова, позволяя апплетам обращаться за данными и возвращать данные компонентам Jaguarа CTS (сервлетам), даже если они были сформированы на основе различных компонентных моделей. Например, апплета, написанная на Java может вызывать сервлеты, созданные на основе ActiveX или объектов C++, работающие на сервере Jaguar CTS в том же самом сеансе.
Интеграция инструментальных средств быстрой разработки приложений
Разработчики могут использовать любой инструментарий для разработки апплет и сервлет Jaguar CTS, включая:
PowerBuilder, Power++ и PowerJ от Powersoft - подразделения инструментальных средств Sybase.
Microsoft VisualJ++, Visual Basic и VisualC++.
Популярные инструментальные средства разработки Java, включая Cafe Symantec.
Приложения интегрируются в среду Jaguar CTS, используя wizard’ы и Package Manager
Jaguar CTS Package Manager
WebOLTP приложения состоят из ряда элементов, включая страницы, апплеты и сервлеты, которые должны совместно управляться и работать. Большинство инструментальных средств, однако, реализуют только какой-либо один фрагмент общей картины, предоставляя разработчикам или администраторам самим вручную координировать работу всего комплекса. Jaguar CTS решает эту проблему, предоставляя разработчикам уникальное средство, обладающее большими возможностями, - Package Manager, который позволяет группировать все связанные элементы и компоненты вместе для простого управления и развертывания.
Package Manager обладает такими свойствами как:
Легкий в использованиии графический интерфейс пользователя Java, который позволяет разработчикам динамически развертывать компоненты. Импортирует компоненты из библиотек типов (Type Libraries) ActiveX, интерфейсных файлов Java или CORBA IDL. Позволяет разработчикам определять транзакции и процедуры защиты для каждого компонента или пакета. Интегрируется с Jaguar CTS Manager для runtime мониторинга и администрирования.
Обработка результирующих выборок
Одна из действительно сильных сторон систем клиент/сервер - это способность хорошо обрабатывать результирующие выборки. В двухуровневых системах клиент/сервер, чтобы отобразить и обработать результаты выборки из базы данных, разработчик просто применяет средства управления связанными данными (или PowerBuilder DataWindow) к схеме БД. Эти средства затем автоматически генерируют заданную по умолчанию логику представления, чтобы отобразить полученные результаты. Почти во всех многоуровневых системах это не такая простая задача. Разработчик должен сначала исследовать бизнес-логику, заложенную в ПО промежуточного уровня, чтобы определить, каков будет получен результат, если он вообще возможен. Разработчик должен затем вручную программирует обработку циклов и графику представления для клиентской части.
Jaguar CTS действительно решает эту фундаментальную проблему. Во-первых, Jaguar CTS имеет мощный встроенный API обработки результирующих выборок, доступный всем клиентским апплетам. Во-вторых, Jaguar CTS позволяет разработчикам определять результат, который возвращается компонентом. Таким образом, существующие DataWindow и другие средства управления связанными данными могут автоматически генерировать логику представления для тонких клиентов.
Интеграция компонентов третьих фирм
Так как Jaguar CTS поддерживает стандартные компонентные модели, то для работы с ним могут быть приобретены компоненты третьих фирм из широкого диапазона имеющихся в настоящее время на рынке. Это улучшает производительность разработчика и ведет к более функциональным приложениям.
Доступные компоненты включают:
Имеющиеся ActiveX и Java компоненты типа электронных таблиц, программ проверки орфографии и инструментальных средств составления диаграмм.
Все внешние сервисы типа электронной торговли и передачи сообщений.
Существующие / приложения.
Защита в Jaguar CTS
Защита - одна из первых проблем, которая приходит на ум при обсуждении WebOLTP приложений. В Jaguar CTS эту важная задача решается с помощью:
Поддержки стандарта Интернет secure socket layer (SSL) для шифрования данных.
Установление подлинности пользователя через “public keys” в SSL.
Защита уровня приложений на основе списков управления доступом (access control list - ACL).
Firewall программа легализации.
Шифрование и авторизация
Jaguar CTS обеспечивает шифрование и авторизацию на основе промышленного secure socket layer (SSL). Все соединения броузеров и сервера Jaguar CTS могут использовать SSL. Кроме того, Jaguar CTS распространяет SSL и на все соединения Jaguar CTS с СУБД, где SSL обеспечивается собственно back-end СУБД. SSL поддержка может также быть избирательно отключена для повышения производительности в безопасных внутренних сетях. Защита на уровне приложений
Jaguar CTS ограничивает возможность выполнение сервлет уполномоченными пользователями на основе списков управления доступом. Доступ может быть ограничен пакетом, компонентом или даже отдельным методом компонента. Защита поддерживается через Jaguarа CTS Manager, о котором было упомянуто ранее. Firewall легализация
Jaguar CTS был проверен и сертифицирован для работы с ведущими firewall-средствами. Где поддержка firewall для специфических протоколов Jaguar CTS не доступна, сервер Jaguar CTS обеспечивает эффективные возможности HTTP-туннелирования. Управление транзакциями в Jaguar CTS
Jaguar CTS предлагает очень гибкое управление транзакциями с поддержкой как обычной синхронной, так и асинхронной обработки запросов (См. Рисунок 7). Подобно остальным частям Jaguar CTS, управление транзакциями открыто и поддерживает множество координаторов транзакций и СУБД.

Рисунок 7. Управление транзакциями в Jaguar CTS.
Синхронное управление транзакциями Диспетчер транзакций Jaguar CTS Transaction Manager с помощью “неявных транзакций” скрывает почти всю сложность координации и управления транзакциями от разработчиков приложений. Управляя неявными транзакциями, разработчики при развертывании компонента определяют, является ли он “транзакционным”. Во времени работы Jaguar CTS Transaction Manager автоматически управляет границами транзакции и гарантирует непротиворечивость транзакции во всех транзакционных компонентов и основной СУБД. При двухфазном коммите (two-phase commit), когда необходимо координировать изменения на множестве СУБД, Jaguar CTS автоматически и непосредственно вызывает Microsoft DTC или XA координатор транзакций. Формирование очереди в базах данных для асинхронного управления транзакциями Хотя синхронная обработка транзакций подходит для многих приложений, увеличивающийся доля WebOLTP бизнес-транзакций порождает множество физических транзакций в ряде новых и старых систем. Например, новая WebOLTP система ввода/регистрации заказов могла бы брать заказы непосредственно от заказчиков через Интернет. Когда заказ размещен, это порождает транзакции в системе доставки и, соответственно, в системе составления счетов (см. Рисунок 7). Каждый шагобязательно выполнится, но только, если пользователь может подождать. Однако непрактично вынуждать пользователя Интернет ждать завершения всех операций во всех подсистемах, потенциально не всегда доступных. Чтобы решить эту проблему, Jaguar CTS предлагает вариант обработки типа “запустил и забыл” (“fire and forget”), с использованием нового сервиса dbQ. С помощью dbQ пользователь просто помещает заказ в систему регистрации, подтверждает его и возвращается к своей работе (или серфингу, шахматам etc.). DbQ, используя надежную передачу сообщений, гарантирует, что системы доставки и учета получат данные о новом заказе. В отличие от универсальных систем передачи сообщений, dbQ использует продвинутую технологию формирования очереди в базе данных, чтобы обеспечить выполнение изменений в системе регистрации заказов и передать сообщение в системе доставки как об успешном завершении, так и об откате транзакции.Основные возможности dbQ включают:
Резидентные очереди в базах данных для обеспечения транзакционной целостности, улучшенной производительности и более простого администрирования. Поддержка ActiveX, JavaBeans и компонентов . Гибкая доставка сообщений, включая fan-in/fan-out, приоритеты и уведомления. Поддержка многих СУБД, включая Sybase SQL Server, SQL Anywhere, Microsoft SQL Server и Oracle Надежная доставка сообщения к другим системам передачи сообщений, включая MQSeries IBM
Сетевое планирование – Кто? Когда? Сколько?
После того, как руководитель проекта получил спецификацию системы, как-то: диаграммы пакетов, диаграммы классов этих пакетов и диаграммы взаимодействия, - то следует приступать к сетевому планированию задач по реализации кода между программистами, которые находятся в его подчинении. Для этой цели, на мой взгляд, следует применять диаграмму Ганта. Пример такой диаграммы изображен на рис. 6.

Рис.6
Сначала руководитель проекта должен создать список ресурсов, т.е. программистов. Потом создать задачи крупного порядка, например, их можно позаимствовать из названий пакетов, и связать эти задачи, дабы установить порядок их исполнения на основе зависимостей между пакетами. Каждой задаче нужно назначить ее предварительную продолжительность. К полученным задачам прикрепить ресурсы (программистов), которые будет их исполнять. Следует внимательно следить за тем, что бы программист не получил задач требующих от него не 8-ми, а 16-ти часовой рабочий день. Далее, следует разбить крупные задачи на более мелкие подзадачи. С помощью так называемого work breakdown structure руководитель проекта должен получить иерархию задач. Это необходимо для того что бы с одной стороны точнее оценить временные затраты на задачи высшего порядка, а с другой стороны, точно сформулировать - что и когда должен делать каждый программист. Для этого этапа рекомендую использовать MS Project. Он позволит удобно и быстро распределить задачи и распечатать листочки с заданиями для программистов.
После того как руководитель проекта получит сетевой график в первом приближении, то уже можно более реалистично увидеть, сколько времени будет длиться проект и сколько ресурсов он требует.
Sharew.shtml
Как стать шареварщиком, или как заработать деньги своим умом.
Олег Сергудаев,
- Программы для надежной работы и интересного отдыха (для Win 95/98/2000/NT). Вам пригодятся наши программы.
Все, так или иначе, пользуются шареварными (условно-бесплатными) программами. Достаточно вспомнить такие программы как Far, WinRar, Windows Commander и много других. А почему же так мало российских программ, что мешает программистам-одиночкам зарабатывать достойные деньги - незнание английского языка, нежелание или что-то еще? В этой статье я поделюсь своим опытом и постараюсь помочь () стать разработчиком шареварных программ. Итак...
Для начала необходимо определиться, на какой рынок ориентироваться: российский (под российским я понимаю и все пространство СНГ) или зарубежный. Мое личное мнение такое, что в России заработать какие-то деньги продажей программ практически невозможно. Потому что программу продавать придется по 100, 200 рублей, дороже никто не купит. Да и сильна в России жажда бесплатного. В этом случае ориентироваться можно только на организации. Но это, значит, ограничивать круг программ, которые могут купить (попробуй, например, предложи начальству купить какой-нибудь красивый скринсейвер).
Кроме того, в нашей стране еще существует такая проблема как кредитные карточки, вернее недостаточная их распространенность. Ведь для того, чтобы купить Вашу программу нужно (как обычно) идти в сберкассу, стоять там очередь, а потом посылать квитанцию автору. Многих уже это останавливает от покупки. Другое дело зарубежные покупатели - не вставая с места, написали номер кредитной карточки, перевели деньги, и покупка состоялась.
Решение как всегда где-то посередине. Основной акцент надо делать на зарубеж, но и поддерживать российскую сторону. Например, продавать в России по низким ценам или раздавать бесплатно. Таким образом, Вы и в российском интернете раскрутитесь и за рубежом. А потом, когда ситуация наладится, можно будет и цены устанавливать. В любом случае Вы окажитесь в выигрыше - Вас будут знать и здесь и там.
Итак, что нужно, для того чтобы продавать свои собственные программы.
Во-первых, как минимум нужно знать какой-нибудь язык программирования (C, Pascal, Visual Basic). Причем не просто знать о нем, а программировать на достаточно хорошем уровне, ведь плохо написанную программу покупать никто не будет (книги типа "Делфи для чайников" здесь не помогут). Во-вторых, необходимо знание языка гипертекстовой разметки (HTML). Обязательно должна быть страничка, где Вы будете представлять свои программы. Причем она должны быть простой, со вкусом, с удобной навигацией, не перегруженной графикой и самой полной информацией о Ваших программах. Здесь () мы так и попытались сделать. Кроме того, читайте книги, смотрите, как сделаны другие такого же плана сайты и пытайтесь сделать лучше. Наконец, самый больной вопрос для русскоязычных граждан - английский язык. Как ни крути, минимальное знание его просто жизненно важно. Ведь и страничку, и помощь по программе, и сам интерфейс программы - все нужно делать на английском языке. Не стоит расстраиваться, если вы не обладаете этими знаниями. Просто нужно объединиться с кем-нибудь, тем более что одному заниматься этим тяжело. А вдвоем, втроем вполне по силам (и по средствам). Например, один пишет программы, второй занимается веб-дизайном, обновляя страничку, третий занимается переводом на английский язык, приходящей почтой и пр. Таким образом, каждый занимается своим любимым делом. К тому же и расходы делить придется поровну, получается не так много, как если б занимался этим один. Вообще можно и вдвоем организоваться и платить переводчику или выплачивать ему процент с продажи. После того, как Вы написали программу, создали страничку необходимо где-то ее разместить и купить доменное имя, если его еще нет. В самом лучшем случае оно должно быть второго уровня (типа ), первый уровень это расширение .com, .ru, .org, .net и пр. Но можно и третьего уровня (), но не больше. Если имя очень длинное, его будет трудно запомнить, да и мне кажется потратить 20 долларов (именно столько стоит доменное имя сроком на 1 год) на доменное имя второго уровня - это не так уж много.
Все это можно приобрести в одном месте () - там же можно заказать и доменное имя (40$ - на два года), и место (10Мб - 10$ в месяц, 50$ - 20$ в месяц, 100Мб - 30$ в месяц). Для шареварщиков есть скидки. У них можно платить в рублях и за доменное имя и за хостинг. Отношение к Вам доброжелательное, и на любой вопрос всегда ответят, да и еще очень подробная статистика по сайту. Рекомендую сразу купить место на 50 Мб, в это случае ограничение на трафик нет. Поясню на примере. Когда посетитель заходит на Ваш сайт, браузер скачивает на диск (память) все картинки, текст и пр. Все это имеет какой-то размер и если посетителей достаточно много, то и размер скаченного достаточно велик. А скачивает он именно с сервера, где расположена Ваша страничка. Например, заглавная страничка занимает 100 Кб. Представьте, что ее посетило 100 человек в день - это составит 10 000 Кб (около 9,7 Мб) плюс Ваши файлы, которые Вы выкладываете, их тоже умножьте на число скачанных. В итоге, к примеру, Ваш трафик получился 30 Мб в день. А теперь эти 30 Мб умножьте на 30 дней - получилось 900 Мб. У многих компаний, предоставляющих хостинг, стоит ограничение на трафик (например, 1 Гб в месяц) - будьте внимательны. Иногда за превышенный трафик берут отдельную плату. В принципе компаний занимающихся хостингом достаточно много, можно найти и дешевле (но не забывайте, что бесплатный сыр только в мышеловке), потому что бывает так, что вроде дешевле, но заставляют баннер на пол страницы вывешивать. Итак, у Вас готова и страничка и программа (программы), есть доменное имя, есть место, где это все разместилось, осталось решить орг. вопросы, а именно куда будут приходить заработанные Вами деньги. Для этого надо открыть два счета (на чье имя - договоритесь между собой) - валютный и рублевый, не забудьте сделать доверенность товарищу, чтобы он в случае Вашего отсутствия мог снять деньги. Сделать это можно в любом банке. Спишите все реквизиты своего банка и особенно Вашего счета. Для чего это нужно? Все эти данные Вы впишите на сайте регистратора.
Регистратор - это компания, которая принимает от покупателей деньги (беря естественно процент от суммы продажи Вашей программы). Они проверяют кредитные карточки, принимают деньги всеми возможными способами, а регистраторы, работающие в России, кроме того, заключают договор с Вами, решая проблему с налогами. Западные регистраторы договор, конечно, пришлют, но с налоговой Вы будете разбираться сами. Будем надеяться, что в скором времени все наладится. Компания обещала решить этот вопрос, сходите, поспрашивайте. Из западных очень рекомендую RegSoft (), из крупных еще ShareIt () , RegNow (), впрочем, их достаточно много, поэтому выбирайте, где сервис получше, а не где процент меньше. Из российских регистраторов - это , , . Первые два регистратора имеют шикарную систему приема денег, она находится по адресу . Вам надо просто зарегистрироваться, зарегистрировать программу и получить ссылку, нажав на которую покупатель сможет купить Вашу программу. Если что не понятно почитайте раздел вопросов и ответов, там все подробно расписано. Теперь у Вас все есть, осталось всего малость, а именно, свои программы нужно разместить на, так называемых, софт-каталогах.
| Из российских это: | Из зарубежных: |
Система координат
В Direct3D она соответствует так называемому правилу "левой руки". Суть правила в том, что если Вы растопырите пальцы левой руки так, что указательный палец будет направлен к экрану, большой к потолку, а средний параллельно столу туда, где обычно лежит мышиный коврик, то большому пальцу будет соответствовать координата Y, среднему - X, указательному Z. Говоря короче координата Z направлена как бы вглубь экрана (я во всяком случае нахожусь по эту его сторону :-)), координата Y - вверх, координата X - вправо (все рисунки из SDK).

Возможно Вам это покажется непривычным. А что Вы тогда скажите на это - в DirectX цвета задаются тремя составляющими R,G,B, каждая из которых - число с плавающей точкой в диапазоне [0-1]. Например белый цвет - (1,1,1), серенький (0.5,0.5,0.5), красный (1,0,0) ну и т.д.
Все трехмерные объекты задаются в виде набора (mesh) многоугольников (граней - faces). Каждый многоугольник должен быть выпуклым. Вообще-то лучше всего использовать треугольники - более сложные многоугольники все равно будут разбиты на треугольники (на это уйдет столь драгоценно процессорное время). Грани (faces) состоят из вершин (vertex).

Грань становится видимой если она повернута так, что образующие ее вершины идут по часовой стрелке с точки зрения наблюдателя. Отсюда вывод - если Ваша грань почему-то не видна - переставьте вершины так, чтоб они были по часовой стрелке.
Кроме того имеются другие объекты - источники света (прямой свет - directional light и рассеянный свет - ambient light), т.н. камера, текстуры, которые могут быть "натянуты" на грани и прочая, прочая: Наборы объектов составляют т.н. frames (затрудняюсь дать этому русское название). В Вашей программе всегда будет хоть один главный frame, называемый сцена (scene), не имющий фрейма-родителя, остальные фреймы принадлежат ему или друг другу.
Я не буду долго разговаривать о том, как инициализировать все это хозяйство, для Дельфи-программиста достаточно разместить на форме компонент TDXDraw из библиотеки DelphiX.
Перейдем однако к делу. Запустите-ка Дельфи и откройте мою (честно говоря не совсем мою - большую часть кода написал Hiroyuki Hori - однако не будем заострять на этом внимание :-)) учебную программку - .
Найдите метод TMainForm.DXDrawInitializeSurface.
Этот метод запускается при инициализации компонента TDXDraw.
Обратите внимание, что DXDraw инкапсулирует D3D, D3D2, D3Ddevice, D3DDevice2, D3DRM, D3DRM2, D3DRMDevice, D3DRMDevice2, DDraw - ни что иное как соответствующие интерфейсы DirectX. (только в названиях интерфейсов Microsoft вместо первой буквы D слово IDirect). Инициализация компонента очень подходящее место, чтоб выбрать кое какие режимы (что и делается в программке). Обратите внимание на DXDraw.D3DRMDevice2.SetRenderMode(D3DRMRENDERMODE_BLENDEDTRANSPARENCY or D3DRMRENDERMODE_SORTEDTRANSPARENCY); - Эти два флага установлены вот для чего - если у нас два треугольника находятся один под другим и оба видны (т.е. вершины у них по часовой) нужно их сперва отсортировать по координате Z чтоб понять кто кого загораживает. Включает такую сортировку флаг, названный скромненько эдак, по Microsots-ки: D3DRMRENDERMODE_SORTEDTRANSPARENCY. Однако как говаривал К. Прутков - смотри в корень. Корнем же у нас является метод TMainForm.DXDrawInitialize(Sender: TObject);
Здесь сначала создаются два фрейма - Mesh и Light, для нашего видимого объектика и для лампочки, его освещающей. MeshFrame.SetRotation(DXDraw.Scene, 0.0, 10.0, 0.0, 0.05);
(первые три цифры - координаты вектора вращения, последний параметр - угол полворота) . Тонкое (не очень правда :-)) отличие между методами SetRotation и AddRotation в том, что AddRotation поворачивает объект только один раз, а SetRotation - заставляет его поворачиваться на указанный угол при каждом следующей итерации (with every render tick) Потом создается т.н. MeshBuilder - специальный объект, инкапсулирующий методы для добавления к нему граней. Этот обьект может быть загружен из файла (и естественно сохранен в файл). По традиции файлы имеют расширение X. (насколько мне извесно эта традиция возникла еще до появления сериала X-Files :-)) В самом же деле - в конце 20 века задавать координаты каждого треугольника вручную: Можно заставит сделать это кого то еще - а потом просто загрузить готовый файл :-). Ну а если серьезно в DirectX SDK входит специальная утилита - conv3ds. {conv3ds converts 3ds models produced by Autodesk 3D Studio and other modelling packages into X Files. } Однако создадим объект вручную - ну их эти Х-файлы. Наш объект будет состоять из 4-х граней (ни одного трехмерного тела с меньшим количеством граней я не смог придумать).
Естественно каждая грань - треугольник, имеющий свой цвет. MeshBuilder.Scale(3, 3, 3); - Увеличиваем в три раза по всем координатам.
Наконец MeshFrame.AddVisual(MeshBuilder); - наш MeshBuilder готов, присоединяем его как визуальный объект к видимому объекту Mesh. DXDraw.Scene.SetSceneBackgroundRGB(0,0.7,0.7); -
Как понятно из названия метода цвет фона. (Видите - я не врал RGB-цвет действительно задается числами с плавающей точкой :-)) Интересные дела творятся в методе TMainForm.DXTimerTimer. (небольшая тонкость - это не обычный таймер, а DXTimer из библиотеки DelphiX) DXDraw.Viewport.ForceUpdate(0, 0, DXDraw.SurfaceWidth, DXDraw.SurfaceHeight);
указываем область, которую нужно обновить (не мудрствуя лукаво - весь DXDraw.Surface) DXDraw.Scene.Move(1.0);
- применяем все трехмерные преобразования, добавленные методами вроде AddRotation и SetRotation к нашей сцене. (вот где собака то порылась: :-) вычисления новых координат точек начнутся не сразу после метода AddRotation а только здесь) DXDraw.Render - Рендерим (ну как же это по русски то? :-)) DXDraw.Flip - выводим результат рендеринга на экран (аминь :-));
(в этом методе помещены также несколько строк, выводящих на экран число кадров в секунду и информацию о поддержке Direct3D аппаратурой или программно - пригодится при отладке) Метод FormKeyDown.
Здесь проверяется код нажатой клавиши - если Alt+Enter - переходим из оконного в полноэкранный режим (клево, правда? :-)) и наоборот. Напоследок пара слов о DXDrawClick. Просто выводим FileOpenDialog - Вы можете поэкспериментировать с x-файлами. Пока все. Пишите: ,
Описанный в статье пример Вы можете скачать (198К).
Продолжение (на сайте ): Часть I:
Часть II:
Часть III:
Сложность реализации
Предложенная мной спецификация имеет точки соприкосновения со спецификацией EJB в плане целей, но не содержит ограничения на архитектуру безопасности, бизнес-объектов и их описаний. Спецификация не имеет узкую направленность на конкретную распределенную технологию, такую как RMI, и определяет архитектуру клиентских приложений, чего нет в спецификации EJB. Использование уже готовых реализаций спецификации EJB очень привлекательно по сравнению с самостоятельной реализацией, предложенной мной спецификации, но в силу своих ограничений может быть отвергнута. Для получения первой версии реализации спецификации каркаса системы с распределенной архитектурой было затрачено шесть месяцев группой программистов из 6 человек с 8 часовым рабочим днем и 5 дневной рабочей неделей. Для тех организаций, которые решили воспользоваться данной спецификацией, следует предварительно просчитать все плюсы и минусы ввязывания в данную разработку.
инспектора объектов показывает список событий,
Страница событий (Events) инспектора объектов показывает список событий, распознаваемых компонентом (программирование для операционных систем с графическим пользовательским интерфейсом, в частности, для Windows 95 или Windows NT предполагает описание реакции приложения на те или иные события, а сама операционная система занимается постоянным опросом компьютера с целью выявления наступления какого-либо события). Каждый компонент имеет свой собственный набор обработчиков событий. В C++ Builder следует писать функции, называемые обработчиками событий, и связывать события с этими функциями. Создавая обработчик того или и ого события, вы поручаете программе выполнить написанную функцию, если это событие произойдет. Для того, чтобы добавить обработчик событий, нужно выбрать на форме с помощью мыши компонент, которому необходим обработчик событий, затем открыть страницу событий инспектора объектов и дважды щелкнуть левой клавишей мыши на колонке з ачений рядом с событием, чтобы заставить C++ Builder сгенерировать прототип обработчика событий и показать его в редакторе кода. При этом автоматически генерируется текст пустой функции, и редактор открывается в том месте, где следует вводить код. Курсор позиционируется внутри операторных скобок { ... }. Далее нужно ввести код, который должен выполняться при наступлении события. Обработчик событий может иметь параметры, которые указываются после имени функции в круглых скобках.

Составные части MetaBASE
MetaGen - менеджер проектов MetaBASE (написанный на Delphi). Он транслирует модель данных в объекты MetaBASE и сохраняет их в специализированном словаре данных (Metamodel). Позже этот словарь данных используется как средой разработки Delphi, так и разработанным приложением во время выполнения.
MetaGen также может осуществлять перенос измененных объектов MetaBASE обратно в модель данных. Иными словами, это полноценный инструмент two-way-tool.
Metamodel - объект, который содержит всю информацию об объектах модели данных - сущностях, индексах, атрибутах, доменах и связях. Кроме того, Metamodel содержит расширенные атрибуты типа масок, меток и т.д., которые могут быть изменены в редакторе MetaBASE Editor.. Все объекты модели данных доступны при создании приложения.
MetaBASE Editor- иерархическое окно просмотра метамодели, позволяющее редактировать модель данных, изменять расширенные атрибуты, синхронизировать модели данных в ER-диаграмме и в словаре данных, выбирать интерфейсные элементы для отображения таблиц и полей, выбирать способ доступа к данным (таблица или запрос). Этот редактор метаданных используется в среде разработки в качестве редактора свойств компонент, входящих в комплект поставки MetaBASE (рис.1).
Библиотека визуальных компонентов MetaBASE, имеющих прямой доступ к словарю данных.. Эти VCL-компоненты существуют в 16-разрядном и 32-разрядном вариантах. Среди них имеются модуль для определения бизнес-правил, осуществляющий связь со словарем данных, наследники стандартных компонент со страниц Data Access и Data Controls, обращающиеся к модели данных во время проектирования и выполнения, а также ряд специфических компонент для отображения данных из связанных таблиц, формулирования и выполнения QBE-запросов, поиска и сортировки по индексам,
Совершенствование процесса и модели зрелости разработки ПО
Миф, связанный с этой тенденцией современной программной инженерии, состоит в следующем: измерение зрелости процесса разработки в некоторой организации эквивалентно измерению качества ПО, которое эта организация производит. Отсюда неявно следует, что построение более зрелого процесса разработки обеспечивает создание более зрелого ( более качественного) ПО.
Само по себе усовершенствование процесса разработки, так же как и ранжирование коллективов по уровню профессионализма (особенно по стандартизованной методике типа CMM) безусловно похвально. Однако практика доказывает, что предположение об однозначной связи между официально засвидетельствованными рейтингами зрелости процессов и качеством производимого ПО ошибочно. К сожалению, в компьютерной индустрии этот миф получил чрезвычайно широкое распространение.
Современная ифраструктура Internet
Современная ифраструктура Internet представлена на Рис.2. и включает в себя:
Web-броузер, служащий для отображения страниц в формате HTML (Hypertext Mark-up Language) Web-сервер, который занимается хранением и управлением HTML-страниц
Рисунок 2. Базовая и расширенная архитектура Web.
Стандартные средства связи между броузером и сервером на основе протокола (Hypertext Transfer Protocol).
Базовая инфраструктура была разработана и до сих пор вполне подходит для публикации статической информации, например, данных маркетинговых исследований.
Как показано на Рис.3, базовая инфраструктура Internet за последнее время была раширена в смысле большей динамичности приложений (интерактивных возможностей пользователей) за счет:
Простых форм запросов и форматирования данных на основе JavaScript для броузера API для Web сервера, таких как, например, NSAPI и ISAPI, позволяющих броузерам вызывать приложения на стороне сервера. Серверов динамической обработки, которые преобразуют данные из БД в страницы в формате HTML (например, "Dynamo").Расширенная инфраструктура Web за счет динамической обработки данных, т.е. способности сервера возвращать данные броузеру в соответствии с запросом пользователя или в другой интерактивной форме, предоставляет возможность создания совершенно нового и важного класса приложений от систем поддержки принятия решения через intranet до персональных новостей в Internet.

Рисунок 3. Новая архитектура для WebOLTP
Однако, даже с учетом этих расширений большинство реализаций Internet-инфраструктур неспособны обрабатывать крупные транзакции. До настоящего времени, различные компании пытались соединять базы данных и Web-серверы вместе. Но без инструментальных средств разработки и администрирования, результаты оказываются в лучшем случае неудобными и сложными в сопровождении.
Создание клиентского приложения для обоих COM объектов
Мы собираемся создать клиентское приложение, которое будет поддерживать два COM объекта GasTankLevelGetter и FishTankLevelGetter. Используя AppWizard, создайте MFC диалог приложения, который бы поддерживал и управляющие элементы Automation, и ActiveX одновременно (укажите это в соответствующих check box во время работы с AppWizard).
Как только вы создали приложение, отредактируйте ваш основной диалог в редакторе ресурсов, так чтобы он имел сходство с следующим:

Следующий шаг состоит в добавлении указателей сообщений для двух кнопок Gas Tank Level и Fish Tank Level. В примере эти методы называются OnGas и OnFish соответственно
Если вы создали класс диалога и добавили указатели сообщений для кнопок, вам необходимо открыть этот класс и добавить несколько членов класса и методов класса. Первое, что мы сделаем, - это опишем далее интерфейс ILevelGetter так, чтобы мы могли добавлять члены класса (class member) для этого типа интерфейса. Во-вторых, добавим два дополнительных метода класса (class methods) ClearMembers и SetNewData и два члена класса m_pILevelGetter и m_sLastCalled. Затем, используя Class Wizard, добавим методы OnDestroy и OnTimer. Как только это сделано, ваше описание класса должно быть таким, как показано ниже.
//forward declaration so for our class member interface ILevelGetter; class CLevelViewerDlg : public CDialog { DECLARE_DYNAMIC(CLevelViewerDlg); friend class CLevelViewerDlgAutoProxy; public: CLevelViewerDlg(CWnd* pParent = NULL); // standard constructor virtual ~CLevelViewerDlg(); //{{AFX_DATA(CLevelViewerDlg) enum { IDD = IDD_LEVELVIEWER_DIALOG }; //}}AFX_DATA //{{AFX_VIRTUAL(CLevelViewerDlg) protected: virtual void DoDataExchange(CDataExchange* pDX); // DDX/DDV support //}}AFX_VIRTUAL // Implementation protected: CLevelViewerDlgAutoProxy* m_pAutoProxy; HICON m_hIcon; BOOL CanExit(); //added by manually typing these into the class void ClearMembers(); void SetNewData(const CLSID& clsid, const IID& iid); ILevelGetter* m_pILevelGetter; CString m_sLastCalled; // Generated message map functions //{{AFX_MSG(CLevelViewerDlg) virtual BOOL OnInitDialog(); afx_msg void OnPaint(); afx_msg HCURSOR OnQueryDragIcon(); afx_msg void OnClose(); virtual void OnOK(); virtual void OnCancel(); //added by the Class Wizard afx_msg void OnFish(); afx_msg void OnGas(); afx_msg void OnDestroy(); afx_msg void OnTimer(UINT nIDEvent); //}}AFX_MSG DECLARE_MESSAGE_MAP() };Далее изменим файл описания реализации (implementation file).
В конструкторе класса проинициализируйте переменные членов класса как это показано ниже:
//-------------------------------------------------------------- CLevelViewerDlg::CLevelViewerDlg(CWnd* pParent /*=NULL*/) : CDialog(CLevelViewerDlg::IDD, pParent) { //{{AFX_DATA_INIT(CLevelViewerDlg) //}}AFX_DATA_INIT m_hIcon = AfxGetApp()->LoadIcon(IDR_MAINFRAME); m_pAutoProxy = NULL;
m_pILevelGetter = NULL; m_sLastCalled = _T("CheckedGas"); }
Реализация метода ClearMembers приводится далее. Эта функция очищает элементы управления диалога (dialog controls). (Отметим, что мы использовали бы Dialog Data exchange для членов класса.)
//-------------------------------------------------------------------- void CLevelViewerDlg::ClearMembers() { CWnd* pWnd = GetDlgItem(IDC_TANK_TYPE); if(pWnd != NULL) pWnd->SetWindowText("");
pWnd = GetDlgItem(IDC_LOWEST_SAFE); if(pWnd != NULL) pWnd->SetWindowText("");
pWnd = GetDlgItem(IDC_HIGHEST_SAFE); if(pWnd != NULL) pWnd->SetWindowText("");
pWnd = GetDlgItem(IDC_CURRENT); if(pWnd != NULL) pWnd->SetWindowText("");
pWnd = GetDlgItem(IDC_MESSAGE); if(pWnd != NULL) pWnd->SetWindowText(""); }
OnDestroy, показанный ниже, используется для очистки при закрытии диалога.
//-------------------------------------------------------------------- void CLevelViewerDlg::OnDestroy() { CDialog::OnDestroy(); KillTimer(1); }
Данный класс использует OnTimer для вызова методов кнопок OnFish и OnGas так, что пользователю не требуется нажимать кнопки для обновления данных.
//-------------------------------------------------------------------- void CLevelViewerDlg::OnTimer(UINT nIDEvent) { if(m_sLastCalled == _T("CheckedFish")) OnGas(); else OnFish(); }
Замечание: В реальной жизни предпочтительнее использовать технологию с нажатием кнопок и интерфейс IConnectionPoint. Законченный пример такой реализации вы найдете на http://www.microsoft.com/workshop/prog/com/overview-f.htm.
Виртуальная функция OnInitDialog используется в основном для запуска таймера, хотя она также возвращает данные из GasTankLevelGetter COM DLL.
//-------------------------------------------------------------------- BOOL CLevelViewerDlg::OnInitDialog() { CDialog::OnInitDialog();
SetIcon(m_hIcon, TRUE); // Set big icon SetIcon(m_hIcon, FALSE); // Set small icon
OnGas(); //obtain data SetTimer(1, 4000, NULL); //set timer for 4 seconds
return TRUE; // return TRUE unless you set the focus to a control }
Теперь мы готовы описать реализацию наших методов кнопок OnFish и OnGas, которые вызываются попеременно каждые 4 секунды. Обе эти функции идентичны на процедурном уровне; они передают CLSID и IID в SetNewData. Единственная разница состоит в том, что CLSID
и IID, передаваемые методом OnGas, используются в GasTankLevelGetter, а CLSID и IID передаваемые методом OnFish, - в FishTankLevelGetter.
OnGas возвращает CLSID, взятый из строки GUID, которая имеется в данных coclass TypeLib. Таким же образом возвращается IID и, кроме того, он отображается в OLE/COM Object Viewer. Как только получены GUID, вызывается SetNewData.
//-------------------------------------------------------------------- void CLevelViewerDlg::OnGas() { m_sLastCalled = _T("CheckedGas"); CLSID clsid; IID iid; HRESULT hRes; hRes = AfxGetClassIDFromString( "{8A544DC6-F531-11D0-A980-0020182A7050}", &clsid);
if(SUCCEEDED(hRes)) { hRes = AfxGetClassIDFromString( "{8A544DC5-F531-11D0-A980-0020182A7050}", &iid);
if(SUCCEEDED(hRes)) SetNewData(clsid, iid); } }
Метод SetNewData, показанный ниже, создает instance в GasTankLevelGetter COM объекте или FishTankLevelGetter COM объекте в зависимости от CLSID. После этого SetNewData вызывает методы интерфейса ILevelGetter для получения данных.
//-------------------------------------------------------------------- void CLevelViewerDlg::SetNewData(const CLSID& clsid, const IID& iid) { ClearMembers();
ASSERT(m_pILevelGetter == NULL);
HRESULT hRes = CoCreateInstance(clsid, NULL, CLSCTX_ALL, iid, (void**)&m_pILevelGetter);
if(!SUCCEEDED(hRes)) { m_pILevelGetter = NULL; return; }
long lLowestSafeLevel, lHighestSafeLevel, lCurrentLevel; BSTR bstrMessage = NULL;
m_pILevelGetter->GetLowestPossibleSafeLevel(&lLowestSafeLevel); m_pILevelGetter->GetHighestPossibleSafeLevel(&lHighestSafeLevel); m_pILevelGetter->GetCurrentLevel(&lCurrentLevel); m_pILevelGetter->GetTextMessage(&bstrMessage);
m_pILevelGetter->Release(); m_pILevelGetter = NULL;
CString sLowest, sHighest, sCurrent, sMessage; sLowest.Format("%d",lLowestSafeLevel); sHighest.Format("%d",lHighestSafeLevel); sCurrent.Format("%d",lCurrentLevel); sMessage = bstrMessage; ::SysFreeString(bstrMessage);
CString sItem; if(m_sLastCalled == _T("CheckedFish")) { //we are checking the fish tank now sItem = _T("Fish Tank"); } else //m_sLastCalled == _T("CheckedGas") { //we are checking the fish tank now sItem = _T("Gas Tank"); }
CWnd* pWnd = GetDlgItem(IDC_TANK_TYPE); if(pWnd != NULL) pWnd->SetWindowText(sItem);
pWnd = GetDlgItem(IDC_LOWEST_SAFE); if(pWnd != NULL) pWnd->SetWindowText(sLowest);
pWnd = GetDlgItem(IDC_HIGHEST_SAFE); if(pWnd != NULL) pWnd->SetWindowText(sHighest);
pWnd = GetDlgItem(IDC_CURRENT); if(pWnd != NULL) pWnd->SetWindowText(sCurrent);
pWnd = GetDlgItem(IDC_MESSAGE); if(pWnd != NULL) pWnd->SetWindowText(sMessage); }
Поскольку интерфейсы одинаковы, мы уверены, что методы будут работать с обоими COM объектами.
Последние два шага должны реализовать OnFish и включить определение интерфейса.
//-------------------------------------------------------------------- void CLevelViewerDlg::OnFish() { m_sLastCalled = _T("CheckedFish"); CLSID clsid; IID iid; HRESULT hRes = AfxGetClassIDFromString( "{7F0DFAA3-F56D-11D0-A980-0020182A7050}", &clsid);
if(SUCCEEDED(hRes)) hRes = AfxGetClassIDFromString( "{7F0DFAA2-F56D-11D0-A980-0020182A7050}", &iid);
if(SUCCEEDED(hRes)) SetNewData(clsid, iid); }
Определение интерфейса, созданное чисто виртуальными членами класса, включается в верхнюю часть файла описания реализации ( хотя его можно поместить в описание класса или отдельный .h файл), так что член класса m_pILevelGetter типа ILevelGetter* "знает" свои методы. Определение интерфейса представлено ниже:
//------------------------------------------------------------------ interface ILevelGetter : public IUnknown { public: virtual HRESULT STDMETHODCALLTYPE GetLowestPossibleSafeLevel(long* plLowestSafeLevel) = 0; virtual HRESULT STDMETHODCALLTYPE GetHighestPossibleSafeLevel(long* plLowestSafeLevel) = 0; virtual HRESULT STDMETHODCALLTYPE GetCurrentLevel(long* plLowestSafeLevel) = 0; virtual HRESULT STDMETHODCALLTYPE GetTextMessage(BSTR* pbstrMessage) = 0; };
Теперь мы готовы откомпилировать, слинковать и запустить приложение. Если вы запустили приложение, вы можете щелкнуть по какой-либо кнопке, чтобы переключить COM компоненты, или позволить таймеру переключать их автоматически каждые четыре секунды. И только теперь Ричи Рич сможет спокойно лететь на своем вертолете и следить за уровнем воды в своем аквариуме.
Создание меню
Итак, создадим меню для нашего редактора. Для этой цели поместим на главную фо му приложения компонент TMainMenu со страницы Standard. Нажав правую клавишу мыши, из контекстного меню выберем пункт Menu Designer. Перемещаясь с помощью стрелок клавиатуры, создадим новые компоненты - пункты меню верхнего и последующего уровней, вводя текстовые строки в колонку значений напротив свойства Caption.
Создадим следующие меню: "&Файл" (с пунктами "Созд&ать", "&Открыть...", "&Сохранить", "Сохранить &как...", '"-","В&ыход"), "&Вид" (с пунктом "&Инструментальная панель"), "&Редактирование" (с пунктами "&Вырезать" "&Копировать", "Вс&тавить") и "&?" с пунктом "&О программе".
Если в свойстве Caption какого-либо пункта меню стоит знак "-", в этом месте появится горизонтальная разделительная линия.
Значок "&" нужен для связывания с пунктом меню так называемых "горячих" клавиш. Если перед какой-либо буквой в названии пункта меню стоит такой значок, то при отображении меню эта буква оказывается подчеркнутой, и нажатие на соответствующую уквенную клавишу при нажатой клавише Alt приведет к активизации соответствующего пункта меню. Разумеется, в одном меню все "горячие" клавиши должны быть разными, хотя C++ Builder этого не проверяет.
Помимо этого, для работы с меню с помощью клавиатуры используются клавиши быстрого доступа. Подходящую комбинацию клавиш можно выбрать, установив значение свойства ShortCut.

Рис. 14. Создание меню с помощью Menu Designer.
Теперь в инспекторе объектов выберем страницу событий и свяжем уже созданные функции SpeedButton1Click, ... SpeedButton9Click с соответствующими пунктами меню, выбрав названия функций из выпадающего списка.
У нас остались неиспользованными пункт меню "Панель инструментов". Присвоим свойству Checked этого пункта меню значение true.
Создадим для пункта меню " Панель инструментов" следующий обработчик события OnClick:
void __fastcall TForm1::N9Click(TObject *Sender) { N9->Checked=!N9->Checked; Panel1->Visible=N9->Checked; }
Наконец, создадим контекстные меню для различных элементов главной формы при ожения. Для этого положим на форму два компонента TPopupMenu - один с пунктами "Вырезать", "Копировать", "Вставить", а второй - с пунктом "Скрыть". Выберем подходящие обработчики события OnClick из имеющихся функций для этих пунктов меню. И, наконец, для компонентов Memo1 и Panel1 выберем из выпадающего списка соответствующие имена контекстных меню. Итак, мы создали текстовый редактор с панелью инструментов, главным и контекстным меню и диалоговой панелью "О программе". Окончательный вид работающего приложения представлен на рис. 15.

тел. (095)932-92-12, 932-92-13,
Создание многозвенных приложений с помощью MIDAS
С помощью Delphi 3 Client/Server Suite и Borland MIDAS Suite корпорации могут повысить производительность современных клиент-серверных информационных систем путем централизации бизнес-правил и правил доступа к данным в среднем звене - сервере приложений, базирующемся на Windows NT. MIDAS предоставляет набор брокеров middleware, оптимизирующих производительность сети, а также архитектуру с "тонким" клиентом, упрощающую функционирование, настройку и поставку приложений. MIDAS также обратно совместим с Borland Entera - многоплатформенным интеллектуальным middleware для широкомасштабных, высокопроизводительных гетерогенных систем масштаба предприятия.
"Разработка, поддержка, поставка распределенных приложений была значительной проблемой для компьютерной индустрии", - заявил Луис Клейман (Louis Kleiman), менеджер Financial Dynamics, консалтингового и учебного центра для разработчиков в Вашингтоне. - "MIDAS и Delphi 3 Client/Server Suite удовлетворяют потребностям наших клиентов с точки зрения легкой разработки, конфигурации и доступа к существующим системам."
Создание обработчиков событий
Теперь напишем обработчики событий OnClick для наших кнопок.
Кнопка SpeedButton3 отвечает за открытие файла для редактирования и отображение имени файла на панели состояния: void __fastcall TForm1::SpeedButton3Click(TObject *Sender) { if (OpenDialog1->Execute()) Memo1->Lines->LoadFromFile(OpenDialog1->FileName); StatusBar1->Panels->Items[0]->Text=OpenDialog1->FileName; }
Кнопка SpeedButton5 отвечает за сохранение редактируемого файла под выбранным именем и отображение имени файла на панели состояния. void __fastcall TForm1::SpeedButton5Click(TObject *Sender) { if (SaveDialog1->Execute()) Memo1->Lines->SaveToFile(SaveDialog1->FileName); StatusBar1->Panels->Items[0]->Text=SaveDialog1->FileName; }
Кнопка SpeedButton2 отвечает за очистку окна редактирования. Однако в случае, когда в редакти уемом буфере содержится набранный текст, следует спросить пользователя, желает ли он сохранить текст. Для этой цели не имеет смысла создавать отдельную форму, содержащую всего-навсего текст вопроса и две кнопки. Более удобно воспользоваться функцией Windows API MessageBox,имеющей четыре параметра:
| hWnd | Идентификатор окна-владельца (число, может быть равным 0) |
| lpText | Текст сообщения (символьная строка) |
| lpCaption | Заголовок панели сообщения (символьная строка) |
| uType | Стиль панели сообщения (целая именованная константа, например, MB_OK, MB_ABORTRETRYIGNORE и др.) - полный список стилей можно найти в справочной системе Borland C++ Builder |
Возвращаемое значение функции MessageBox - целая именованная константа, указ вающая на тип нажатой пользователем кнопки: IDABORT, IDCANCEL, IDIGNORE, IDNO, IDOK, IDRETRY или IDYES. В нашем случае удобно предложить пользователю выбрать о ну из кнопок "Да" или "Нет" и сохранять набранный текст в виде файла, если пользователь нажмет кнопку "Да" (что именно окажется написанным на кнопке - "Да" и и "Yes" - зависит от языковой версии операционной системы).
Для сохранения набранного текста можно использовать готовую функцию SpeedButton5Click.
В соответствии с этим обработчик события при нажатии на кнопку SpeedButton2 будет выглядеть следующим образом:
void __fastcall TForm1::SpeedButton2Click(TObject *Sender) { if (Memo1->Lines->Count>0) { if (MessageBox(0,"Сохранить содержимое окна редактирования? ", "Подтвердите сохранение",MB_YESNO)==IDYES) { SpeedButton5Click(Sender) } }; Memo1->Clear(); StatusBar1->Panels->Items[0]->Text="Без имени"; }
Кнопка SpeedButton1 закрывает окно приложения. В этом случае нужно также предложить пользователю сохранить набранный текст, воспользовавшись только что созданной функцией SpeedButton2Click:
void __fastcall TForm1::SpeedButton1Click(TObject *Sender) { SpeedButton2Click(Sender); Close(); }
Кнопка SpeedButton4 отвечает за сохранение редактируемого файла:
void __fastcall TForm1::SpeedButton4Click(TObject *Sender) { if (StatusBar1->Panels->Items[0]->Text=="Без имени") SpeedButton5Click(Sender); else Memo1->Lines->SaveToFile(StatusBar1->Panels->Items[0]->Text) }
Здесь требуются некоторые пояснения. Если пользователь открыл существующий фай или уже сохранил редактируемый файл под каким-либо именем, оно указано на панели состояния (StatusBar1), и открытие диалога для выбора имени файла уже не требуется. Если же имя файла не определено (пользователь только что создал новый файл), следует вызвать диалог сохранения файла, воспользовавшись функцией SpeedButton5Click. Кнопки SpeedButton6 и SpeedButton7 отвечают за перенос и копирование выделенного в окне редактирования фрагмента текста в буфер обмена.
void __fastcall TForm1::SpeedButton6Click(TObject *Sender) { Memo1->CutToClipboard(); } //-------------------------------------------------------- void __fastcall TForm1::SpeedButton7Click(TObject *Sender) { Memo1->CopyToClipboard(); }
Кнопка SpeedButton8 отвечает за сохранение редактируемого файла:
void __fastcall TForm1::SpeedButton8Click(TObject *Sender) { Memo1->PasteFromClipboard(); }
Кнопка SpeedButton9 отвечает за вывод на экран диалоговой панели "О программе".
Наличие подобной иалоговой панели является стандартом для современных приложений. Для разнообразия воспользуемся готовым шаблоном панели About из репозитория объектов C++ Builder. Выберем пункт меню File/New и со страницы Forms блокнота, содержащегося в диалоговой панели New Items, выберем шаблон AboutBox с опцией Copy. Отредактируем полученную форму:


Создание отчетов "master-detail"
Преобразуем созданный отчет в отчет "master-detail". Для этогоследует добавить компонент TTable, установить его свойство DatabaseNameравным BCDEMOS, свойство TableName равным ORDERS.DB, а затем установитьсвойство Active равным true. После этого установим свойство MasterSourceравным DataSource1. Затем выберем свойство MasterFields, вызвав диалоговуюпанель для установки связи master/detail (рис. 4 ) и из списка доступныхиндексов выберем CustNo. Затем выделим имя поля CustNo в обоих спискахполей и нажмем кнопку Add, а кнопку OK.

Рис. 4. Установка связи master/detail
Добавим на форму компонент TDataSource, установив его свойство DataSetравным Table2 . Затем добавим к форме новый компонент TQRBand (c именемQRBand6). После этого добавим компонент TQRDetailLink, предназначенныйдля установки связей между источниками данных в отчетах, и установим егосвойство DataSource равным DataSource2. Затем установим его свойство Masterравным QuickReport, а свойство DetailBand равным QRBand6. Свойство BandTypeкомпонента QRBand6 автоматически примет значение rbSubDetail.
Наконец, поместим два компонента TQRDBText на QRBand6, установим ихсвойства DataSource равными DataSource2, а свойства DataField равными OrderNoи AmountPaid. Слева от них поместим два компонента TQRLabel с названиямиэтих полей (рис. 5).

Рис. 5. Форма отчета "master-detail".
Выберем опцию Preview Report из контекстного меню компонента QuickReportдля предварительного просмотра отчета (рис.6).

Рис. 6. Отчет "master-detail".
Отметим, что если компонент QuickReport не связан с компонентом DataSource,то при печати отчета выводится только одна запись из набора данных, чтолегко позволяет печатать текущую запись.
Создание приложений с помощью MetaBASE
Разработка информационных систем с помощью MetaBASE отличается от традиционной разработки главным образом почти полным отсутствием написания кода в случаях, когда, казалось бы, это необходимо. Чтобы убедиться в этом, рассмотрим небольшой пример, основанный на использовании части модели данных и части самих данных из реально выполнявшегося проекта, включающего в качестве одной из задач хранение и обновление списка предприятий одной из отраслей промышленности.
Первым этапом создания информационной системы является анализ предметной области, проектирование на его основе логической схемы будущей базы данных (определение сущностей, атрибутов и связей), создание соответствующей физической схемы и, наконец, генерация объектов базы данных (таблиц, сущностей, атрибутов). Для этой цели используется ERwin (в нашем случае версии 2.6 beta). Центральная сущность Objects1 связана с другими сущностями посредством внешних ключей. Структура модели данных выглядит следующим образом (рис.2):
Соответствующая физическая структура была сгенерирована на сервере Oracle Workgroup Server 7.2 for Windows NT, и в таблицы был занесен тестовый набор данных.
Так как приложение должно иметь доступ к модели данных во время выполнения, следующим шагом является перенос метаданных в словарь данных MetaBASE (рис.3) и создание соответствующих BDE-алиасов (псевдонимов), при этом имя проекта в утилите MetaGen и имя соответствующего алиаса должны совпадать. Для простоты будем хранить словарь данных и саму базу данных под одними тем же псевдонимом.
Далее выбираем нужный нам файл ER-диаграммы формата .erx, выбираем BDE-алиас для хранения словаря данных и осуществляем перенос метаданных в созданный словарь данных.
После переноса метаданных можно отредактировать их с помощью MetaBASE Editor (рис.1).
Теперь можно приступить к созданию клиентского приложения. Для этого нужно создать в Delphi новый проект и поместить на пустую форму компонент MetaBaseGS

Далее нужно присвоить свойству DataBaseName в инспекторе объектов Delphi имя соответствующего BDE-алиаса (в нашем случае NUCLEAR), а свойству Connected значение 'true'.
С этого момента среде разработки станут доступны метаданные, перенесенные ранее на сервер.После двойного щелчка мышью на этом компоненте появится окно MetaBASE Editor (рис.5). Для начала создадим броузер для просмотра и редактирования списка предприятий. Для этой цели нажмем в окне MetaBASE Editor кнопки





С этой целью добавим компонент IdxControllerGS



Создание приложений в С++ Builder
Первым шагом в разработке приложения C++ Builder является создание проекта. Файлы проекта содержат сгенерированный автоматически исходный текст, который становится частью приложения, когда оно скомпилировано и подготовлено к выполнению. Чтобы создать новый проект, нужно выбрать пункт меню File/New Application.
C++ Builder создает файл проекта с именем по умолчанию Project1.cpp, а также make-файл с именем по умолчанию Project1.mak. При внесении изменений в проект, таких, как добавление новой формы, C++ Builder обновляет файл проекта.

Рис.7 Файл проекта
Проект или приложение обычно имеют несколько форм. Добавление формы к проекту создает следующие дополнительные файлы: Файл формы с расширением.DFM, содержащий информацию о ресурсах окон для конструирования формы Файл модуля с расширением.CPP, содержащий код на C++. Заголовочный файл с расширением .H, содержащий описание класса формы.
Когда вы добавляете новую форму, файл проекта автоматически обновляется.
Для того чтобы добавить одну или более форм к проекту , выберите пункт меню File/New Form. Появится пустая форма, которая будет добавлена к проекту. Можно воспользоваться пунктом меню File/New, выбрать страницу Forms и выбрать подходящий шаблон из репозитория объектов.

Рис.8 Шаблоны форм
Для того, чтобы просто откомпилировать текущий проект, из меню Compile нужно выбрать пункт меню Compile. Для того, чтобы откомпилировать проект и создать исполняемый файл для текущего проекта, из меню Run нужно выбрать пункт меню Run. Компоновка проекта является инкрементной (перекомпилируются только изменившиеся модули).
Если при выполнении приложения возникает ошибка времени выполнения, C++ Builder делает паузу в выполнении программы и показывает редактор кода с курсором, установленным на операторе, являющемся источником ошибки. Прежде чем делать необходимую коррекцию, следует перезапустить приложение, выбирая пункт меню Run из контекстного меню или из меню Run, закрыть приложение и лишь затем вносить изменения в проект. В этом случае уменьшится вероятность потери ресурсов Windows.
Создание простого отчета
Отчеты QuickReport основаны на наборе горизонтальных полос (bands).При построении отчета на форму помещаются несколько компонентов QRBand(наследник TPanel) различных типов.
Для создания простейшего отчета разместим на форме следующие компоненты(рис. 1): TQRBand - компонент, представляющий собой часть отчета - контейнердля размещения данных (например, заголовок отчета, верхний или нижний колонтитулстраницы, верхний или нижний колонтитул группы и др.). Компоненты TQRBandпечатаются в зависимости от их типа в необходимых местах отчета, независимоот их взаимного расположения на форме. Наиболее часто используемое свойствоэтого компонента – BandType, тип "полосы" (колонтитул страницыили группы, "полоса" данных и др.). Возможные значения: rbTitle– заголовок отчета, rbPageHeader – верхний колонтитул страницы, rbColumnHeader– верхний колонтитул колонки в многоколоночном отчете, rbDetail – полосас табличными данными (повторяется столько раз, сколько строк имеется внаборе данных, авляющемся основой отчета), rbPageFooter – нижний колонтитулстраницы, rbOverlay – фон страницы, печатается в левом верхнем углу каждойстраницы, rbGroupHeader – заголовок группы, rbSubDetail – "полоса"табличных данных для Detail-таблицы, rbGroupFooter – нижний колонтитулгруппы, rbSummary – печатается в конце отчета). Свойству BandType созданногонами компонента присвоим значение rbTitle TQuickReport (этот компонент отвечает за превращение формы в отчет). TQRLabel, помещенный на QRBand1 (этот компонент предназначен для выводастатического текста, и его свойству Caption можно присвоить значение, равноетексту заголовка будущего отчета).

Рис. 1. Создание заголовка отчета
Если нажать правую клавишу мыши над компонентом QuickReport1 и выбратьиз контекстного меню опцию Preview Report, появится окно просмотра, в которомбудет отображена страница отчета с созданным заголовком.
Для модификации отчета следует изменить свойство BandType компонентаQRBand1 на rbDetail и добавить на форму компонент TTable.
Далее нужно установитьего свойство DataBase равным имени псевдонима, например, BCDEMOS, свойствоTableName равным имени таблицы, например, CUSTOMER.DB, а затем свойствоActive равным true. После этого нужно добавить на форму компонент TDataSourceи установить его свойство DataSet равным имени добавленного ранее компонентаTable1, а затем установить свойство DataSource компонента QuickReport равнымимени созданного компонента DataSource1. После этого можно добавить компонентTQRDBText на QRBand1(этот компонент предназначен для вывода содержимогополей таблицы или запроса, служащего источником данных проектируемого отчета),установить свойство DataSource равным имени созданного ранее компонентаDataSource1 и выбрать нужное поле в качестве значения свойства DataField.Если есть необходимость, можно добавить другие компоненты TQRDBText и выбратьдругие поля таблицы для отображения в отчете (рис. 2).


Список литературы
C.D.Locke, "Fundamentals of Real-Time", Lockhead Martin, 1998 "Realtime CORBA", White Paper -Issue 1.0, 1996/Dec "It's all a question of time...", Real-time magazine, 1997/4th Quarter R.O'Farrel, "Choosing a cross-debugging methodology", Embedded systems programming, 1997/Aug K.Clohessy, "Using object-oriented programming tools to build real-time embedded systems", Real-time engineering, 1996/Fall V.Encontre, "How to use modeling to implement verifiable, scalable, and efficient real-time application programs", Real-time engineering, 1997/Fall N.Osawa, H.Morita, T.Yuba, "Animation for perfomance debugging of parallel computing systems", ACM, 1997 S.K.Damodaran-Kamal, J.M.Francioni, "Nondeterminacy: testing and debugging in message passing parallel programs", ACM, 1993 M.Timmerman, F.Gielen, P.Lambrix, "High level tools for the debugging of real-time multiprocessor systems", ACM, 1993 A.von Mayrhauser, A.M.Vans, "Program understanding behavior during debugging of large scale software", ACM, 1997 J.Lang, O.B.Stewart, "A study of the applicability of existing exception-handling techniques to component-based real-time software technology", ACM, 1998 P.Fritzson, T.Gyimothy, M.Kamkar, N.Shahmehri, "Generalized algorithmic debugging and testing", ACM, 1991 D.Zernik, L.Rudolph, "Animating work and time for debugging parallel programs. Foundation and experience", ACM, 1991 J.M.Francioni, L.Albright, J.A.Jackson, "Debugging parallel programs using sound", ACM, 1991 T.Kunz, "Process clustering for distributed debugging", ACM, 1993 J.Cuny, G.Forman, A.Hough, J.Kundu, C.Lin, L.Snyder, D.Stemple, "The Ariadne debugger: scalable application of event-based abstraction", ACM, 1993 J.May, F.Berman, "Panorama: a portable, extensible parallel debugger", ACM, 1993 В.В.Липаев, Е.Н.Филинов, "Мобильность программ и данных в открытых информационных системах.", РФФИ, 1997 A.J.Offutt, J.H.Hayes "A semantic model of program faults", ACM, 1996 C.Jeffery, W.Zhou, K.Templer, M.Brazell "A lightweight architecture for program execution monitoring", ACM SIGPLAN 1998/july L.Mittag "Multitasking design and implementation", Embedded system programming, 1998/march E.Ryherd "Software debugging on a single-chip system", Embedded system programming, 1998/march N.Cravotta "Real-time operating systems", Embedded system programming, 1997/march J.E.Stroemme "Integrated testing and debugging of concurrent software systems", the sixth IFIP/ICCC conference on information network and data communication, Trondheim, Norway, 1996/june J.Ready "Distributed applications bend RTOS rules", CMP Media Inc., 1996 J.Tsai, Y.Bi, S.Yang, R.Smith "Distributed real-time systems. Monitoring, visualization, debugging, and analysis", Wiley-Interscience Publication, 1996 В.Б.Бетелин, В.А.Галатенко "ЭСКОРТ - инструментальная среда программирования.", Юбилейный сборник трудов институтов Отделения информатики РАН. Том. II. Москва, 1993.